

Vergleich der besten Software und Anbieter für Datenbereinigung
Damit ein Softwaresystem oder ein organisatorischer Prozess uneingeschränkt funktionieren kann, ist die zugrundeliegende Datenqualität ebenso wichtig, wenn nicht sogar wichtiger als die technischen Systeme und Softwareplattformen, die für die Kontinuität und Genauigkeit der Geschäftsabläufe von den Daten abhängen.
Leider haben aber die Verfügbarkeit und die Bereitschaft der Unternehmen, die Datenqualität zu erhalten und zu verbessern, im Vergleich zu anderen Technologien nicht mit dem Tempo Schritt gehalten.
Seit 2021, unmittelbar nach der ersten öffentlichen Ankündigung der konversationellen KI-Plattform ChatGpt und der anschließenden Enthüllung von agentenbasierten Systemen, die eine Vielzahl von Aufgaben autonom ausführen können, ist die Debatte über Datenqualität wieder in aller Munde.
Dies gilt umso mehr, als Unternehmen zu der Erkenntnis gelangt sind, dass selbst die besten technologiegestützten Systeme nutzlos oder ungenau in ihren Ergebnissen sind, wenn die zugrunde liegenden Daten unvollständig, doppelt vorhanden, unzuverlässig und nicht mit anderen Datenverwaltungssystemen synchronisiert sind.
Die nachstehende Grafik zeigt einen Anstieg der Suchanfragen von Nutzern, die sich über Datenbereinigungsdienste und -tools informieren möchten, um die Einhaltung von Schwellenwerten für die Datenqualität sicherzustellen.
Um Einkäufer, Beschaffungsexperten, Datenmanagement- und GTM-Teams mit den richtigen Informationen auszustatten, stellt dieser Artikel einige der führenden Plattformen zur Datenbereinigung zusammen, die grob in die folgenden Kategorien eingeteilt sind.
- CRM Datenbereinigungssoftware
- ERP-Datenbereinigungssoftware
- Bereinigung von Mitarbeiter- und HR-Daten
- Einmalige Datenbereinigung [Benutzerdefiniert]
#1, #2 & #3 sind häufige und immer wiederkehrende Anforderungen, vor allem, wenn es keine schlechten Data Governance-Rahmenbedingungen gibt.
Bei #4 handelt es sich jedoch um einzigartige, einmalige Datenbereinigungsanforderungen, die kundenspezifisch sind und in der Regel nicht wiederkehren, da sie auf Projektbasis in Anspruch genommen werden.
In dieser Liste finden Sie außerdem eine breite Palette von Plattformen für Datenbereinigungstools, darunter ETL-Tools, speziell entwickelte Bereinigungssoftware, Open-Source-Plattformen, Datenvorbereitungssoftware usw.
Und da Datenbereinigung ein weit gefasster Begriff ist, werden die in diesem Artikel beschriebenen Tools nach ihren Fähigkeiten bewertet;
- Normalisierung von Datensätzen in ein strukturiertes Format aus einem unstrukturierten Format
- Validierung von Daten
- Anreicherung von Datensätzen
- Deduplizierung
- Integration mit verwandten Datensätzen und Technologiesystemen
CRM Datenbereinigungstools
Die meisten Unternehmen mit einem Umsatz von mehr als einer Million $ verwenden in der Regel ein CRM-System. Ziel des CRM ist es, die einzelnen Phasen der Reise von Interessenten, Leads, Opportunities und Kunden durch den Konversionszyklus zu erfassen und die Teams in Vertrieb, Marketing und Betrieb mit den richtigen Daten auszustatten.
Einige CRMs erfassen sogar Partnerdaten und Assoziationen zwischen Partnern, Leads und Zielkonten.
Diese Daten erodieren jedoch im Laufe der Zeit, da Duplikate, fehlende Informationen und falsche Zuordnungen von Daten bei Go-to-Market- und Business-Teams an der Tagesordnung sind und bewährte Methoden der Datenverwaltung nicht immer eingehalten werden.
Openprise
Openprise vermarktet sich selbst als Plattform für die Datenorchestrierung und -automatisierung, die Unternehmen bei der Verwaltung, Bereinigung und Vereinheitlichung ihrer Daten in Marketing-, Vertriebs- und operativen Systemen helfen soll.
Das Alleinstellungsmerkmal der Software ist die nahtlose Integration in verschiedene GTM-Systeme wie CRM, ERP, Kundendatenplattformen (CDPs), Werbeplattformen und andere Tools von Drittanbietern für die Kontaktaufnahme und das Sammeln von Informationen.
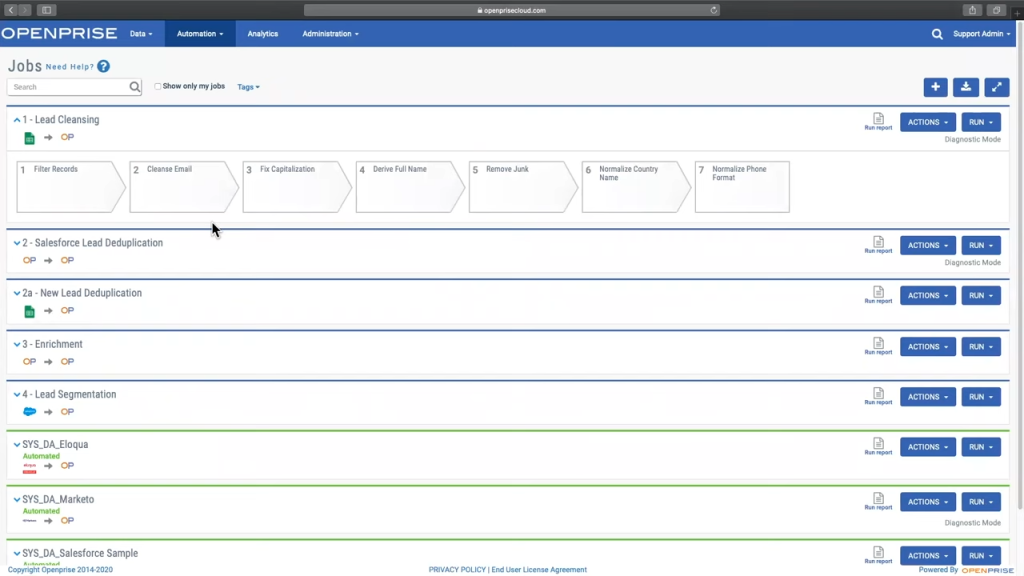
Das Bild unten zeigt, wie OpenPrise Revenue Operations, Performance Marketing und Business-Teams mit sauberen, genauen und zuverlässigen Daten versorgt.
Im Folgenden finden Sie einige der wichtigsten Funktionen.
- Entfernung von Duplikaten auf Kontakt- und Kontoebene - durch die Nutzung von E-Mail-Adressen, Website-Domains, semantischen Mustern und menschlicher Unterstützung
- Validierung von E-Mail-Adressen und Telefonnummern, um Junk-Werte auszusortieren
- Adressen normalisieren, Postleitzahlen,
- Ableitung von Standortdaten aus Telefonnummern
- Ableitung von Stadt- oder Bundeslanddaten aus der Postleitzahl oder umgekehrt
- Standardisierung von Werten und Formaten - zum Beispiel: Großschreibung für Namen, Kleinschreibung für E-Mails usw.
- Die Anreicherung fehlender Werte ist auch durch die Integration von Contact Intelligence-Lösungen von Drittanbietern möglich.
Neben der Datenbereinigung bietet Openprise auch einige Lösungen, um Leads durch Scoring zuzuordnen und sie an den entsprechenden Eigentümer weiterzuleiten.
Bewertungen:
Datenliste
DataBlist positioniert sich als praktisches Tool für Datenqualität und Listenvorbereitung, das sich an Teams richtet, die regelmäßig mit kalkulationsbasierten Datensätzen wie Kontaktlisten, Kundendatensätzen, Produktkatalogen oder durch Veranstaltungen generierten Leads arbeiten.
Die Plattform konzentriert sich in erster Linie darauf, Geschäftsanwendern dabei zu helfen, große Datenmengen zu bereinigen, zu strukturieren und zu standardisieren, ohne dass sie IT-Unterstützung oder irgendeine Art von technischer Skripterstellung oder schwerer Kodierung benötigen.
Seine Stärke liegt in der Bereitstellung eines vertrauten, rasterartigen Arbeitsbereichs, in dem Benutzer schnell Datensätze überprüfen, Korrekturen vornehmen und Werte harmonisieren können, bevor sie die Daten in CRM-, Marketing- oder operative Systeme laden.
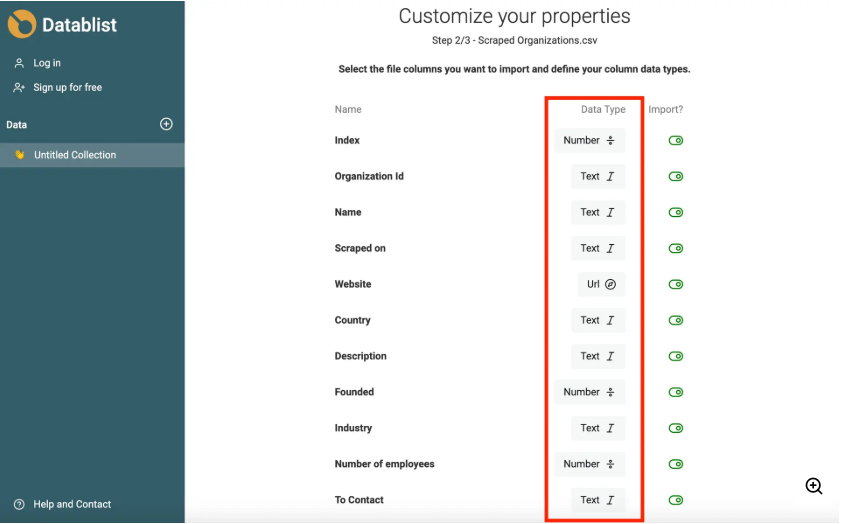
Die folgende Abbildung zeigt, wie Datablist die Duplikate und andere Datenanomalien in Datensätzen erkennt
DataBlist bietet eine Reihe praktischer Funktionen, mit denen Teams Listen bereinigen und vorbereiten können, bevor sie sie in ihre operativen Systeme übernehmen.
- Erkennt Duplikate in Namen, E-Mails, Telefonnummern und Unternehmensfeldern, so dass Benutzer Datensätze sauber überprüfen und zusammenführen können.
- Markiert ungültige E-Mails, falsche Telefonformate und fehlende Pflichtangaben, um Upload-Fehler in CRM- und Marketingsysteme zu vermeiden.
- Normalisiert Großschreibung, Telefon- und E-Mail-Formate und andere inkonsistente Felder in importierten Listen.
- Unterstützt Lookup-basierte Anreicherung und einfache Regeln, um fehlende Zustände, Klassifizierungen oder verwandte Felder aufzufüllen.
- Teilt Langformadressen auf, korrigiert nicht übereinstimmende Stadt-Postleitzahl-Kombinationen und ordnet Postleitzahlen Staaten zu.
- Hilft beim Zuordnen und Ausrichten von Spalten, wenn Sie Listen von Partnern, Veranstaltungen oder älteren Systemen konsolidieren.
- Ermöglicht Massenumwandlungen und bedingte Aktualisierungen mit einem Vorschauschritt, um versehentliche Überschreibungen zu vermeiden.
- Wird als Staging-Ebene verwendet, um sicherzustellen, dass die Daten in Salesforce, HubSpot, Outreach-Tools, Beschaffungssystemen und Berichtsplattformen in einer sauberen und konsistenten Form eingehen.
Insgesamt bietet die Plattform den Betriebs- und RevOps-Teams eine praktische Umgebung, um ihre Daten zu überprüfen, zu korrigieren und zu strukturieren, so dass sie reibungslos in die von ihnen abhängigen Systeme gelangen.
Bewertungen:
Bereinigung von ERP-Stammdaten
Ein ERP-System wird in der Regel vor allem von Großunternehmen eingesetzt und ist weit weniger verbreitet als ein CRM-System.
Normalerweise kann ein ERP-System nicht mit einem CRM-System koexistieren, da es bereits den Großteil des beabsichtigten Zwecks eines CRM-Systems abdeckt. Das muss aber nicht unbedingt der Fall sein.
Ein ERP-System ist auch viel breiter angelegt und kann nicht einmal mit einem CRM-System verglichen werden.
ERP- und EAM-Systeme verwalten alle Funktionen, einschließlich der Produktionsplanung, des Personalwesens, der Finanzverwaltung und der Buchhaltung, sowie marktspezifische Vorgänge.
Diese Systeme werden in der Regel in Unternehmen eingesetzt, in denen das Gesamtvolumen der Datensätze in der Regel recht groß und verstreut ist, was eine Datenbereinigung erheblich erschwert.
Die Arten der Datenbereinigung ändern sich von Zeit zu Zeit.
- Bereinigung von "Material"-Daten
- Bereinigung von "Kunden"-Stammdaten
- Bereinigung von "Lieferanten"-Daten
- Bereinigung von "Dienstleistungen"-Daten
- Bereinigung von "Anlagevermögen" Daten
Verdantis MDM Suite
Verdantis hat sich auf Unternehmenssoftwarelösungen spezialisiert, insbesondere für anlagenintensive Organisationen. Die MDM-Suite von Verdantis ist eine speziell entwickelte Software zur Verwaltung der Stammdatenqualität für Datenbereiche, die für Produktionsdaten spezifisch sind.
Die Software wird auf Datensätze trainiert, die für die unten genannten Branchen spezifisch sind, und setzt agentenbasierte KI ein, um Datenqualitätslücken in allen Stammdatenbereichen zu schließen.
Die beiden in der Verdantis MDM-Suite verfügbaren Module sind Harmonize und Integrity;
Harmonisieren Sie: Dieses Modul konzentriert sich auf die Normalisierung, Bereinigung und Anreicherung alter Stammdatensätze, indem es diese nicht nur aus den ERP- oder EAM-Systemen, sondern auch aus verschiedenen unstrukturierten Quellen wie Lieferantenrechnungen, Anlagenstücklisten, Informationsquellen von Dritten wie D&B, ZoomInfo usw. zusammenführt.
Integrität: Wie der Name schon sagt, ist Integrity ein Modul, das die Verwaltung von Stammdaten löst und dieselben Datenbereiche wie oben erwähnt abdeckt. Dieses Modul lässt sich mit ERP-Systemen mit mehreren oder nur einer Umgebung, Stammdatenstapeln oder EAM-Systemen integrieren, um einen Prozess zu erstellen und jeden Stammdatensatzeintrag direkt an der Quelle zu verwalten.
Das Modul Integrität wurde entwickelt, um sicherzustellen;
- Die Zeit, die für die Erstellung eines Stammdatensatzes benötigt wird, wird verkürzt
- Die Genauigkeit und Vollständigkeit (Integrität) des Stammdatensatzes wird beibehalten, da die Datensätze laufend erstellt werden.
Die Idee hinter Stammdaten, ERPs und Operational Excellence im Allgemeinen ist es, die Ausführungszeit für Aufgaben und die Dateneingabe zu verkürzen. Die Verwaltung von Daten ist eine ressourcenintensive Funktion, vor allem in Bezug auf das Humankapital.
Um dies zu vermeiden, synchronisiert sich Integrity mit anderen Unternehmensmodulen und validiert die Erstellung von Datensätzen in Echtzeit. Dabei werden potenzielle Duplikate und fehlende Pflichtinformationen hervorgehoben.
Es geht sogar noch einen Schritt weiter und setzt KI-Agenten ein, um fehlende Informationen aus verifizierten Drittquellen wie Lieferantenkatalogen, Datenbanken, Nachrichtendienstsoftware und sogar gepflegten Listen von Websites automatisch zu vervollständigen.
Das folgende Video zeigt, wie Integrity innerhalb der MDM-Suite von Verdantis arbeitet, um die Erstellung von Datensätzen zu verwalten und die Stammdatensätze des Unternehmens laufend zu kontrollieren.
Ataccama ONE
Ataccama ist eine einheitliche Datenmanagement-Plattform für Unternehmen, die Stammdatenmanagement (MDM), Datenqualität, Governance und Automatisierung unter einem Dach vereinen möchten.
Das Kernangebot, Ataccama ONE, ist eine integrierte Lösung, die nicht nur MDM, sondern auch Datenprofilierung, Beobachtbarkeit, Lineage, Referenzdaten und KI-gesteuerte Automatisierung unterstützt.
Das folgende Video zeigt Ihnen die wichtigsten Funktionen von Ataccama:
Ataccama ONE ist um modulare Funktionen herum aufgebaut, von denen die beiden wichtigsten sind:
- Datenqualität und Beobachtbarkeit: Das Modul automatisiert die Erstellung von Datenprofilen, KI-gesteuerte Qualitätsprüfungen und Echtzeitüberwachung. Es erkennt Anomalien, schlägt Korrekturen vor und unterstützt die Bereinigung und Anreicherung in allen wichtigen Datenbereichen.
- Stammdatenverwaltung: Das MDM-Modul erstellt domänenübergreifend geregelte, zuverlässige Stammdaten. Es lässt sich mit ERPs und Unternehmenssystemen integrieren, um die Erstellung, Anreicherung, Genehmigung und Veröffentlichung zu verwalten, wobei ein einheitlicher Abgleich und eine Deduplizierung verwendet werden, um einen konsistenten, vertrauenswürdigen Golden Record zu erhalten.
Das Ziel dieses Moduls ist ziemlich einfach:
Reduzieren Sie den Zeitaufwand und die manuelle Arbeit, die mit dem Erstellen oder Aktualisieren von Stammsätzen verbunden sind.
Halten Sie die Daten genau, vollständig und ordnungsgemäß validiert
Verschaffen Sie sich einen klaren Überblick darüber, wer was wann geändert hat, indem Sie die Historie und Genehmigungen verfolgen.
Damit dies funktioniert, prüft Ataccama ONE jeden neuen oder eingehenden Datensatz in Echtzeit. Wenn etwas fehlt, doppelt vorhanden ist oder falsch formatiert wurde, markiert das System dies, bevor die Daten in nachgelagerten Systemen gespeichert werden.
Ataccama arbeitet mit Unternehmen aus dem BFSI-, Telekommunikations-, Pharma- und Regierungssektor zusammen und hat namhafte Kunden wie Aviva, UniCredit, T-Mobile, Roche und Philip Morris International.
Bewertungen:
SAP MDG
SAP ist zweifellos der Pionier und Vorreiter im Bereich ERP-Stammdatenmanagement. MDG, die Abkürzung für Master Data Governance, wurde 2010 von SAP auf den Markt gebracht und erfüllt die Anforderungen von Unternehmen an die Erhaltung der Stammdatenqualität.
Eines der größten Verkaufsargumente für SAP MDG ist die Unterstützung des Ökosystems bei der Extraktion und Zusammenführung von Daten aus SAP-spezifischen Systemen. Anwender können MDG direkt mit ihren SAP-ERPs, EAM, SAP PM und einer ganzen Reihe von SAP-nativer Software extrahieren oder integrieren.
Allerdings gibt es einige Einschränkungen bei SAP MDG, die es Unternehmen erschweren, diese Lösung für ihre Stammdatenanforderungen einzusetzen.
- Begrenzte KI- und Automatisierungsfunktionen
Mit dem "Central Governance"-Modus in SAP S/4HANA (Feature Pack Stack 2) und den Private-Cloud-Editionen unterstützt MDG natürlichsprachliche Eingabeaufforderungen für Feldänderungen und kann automatisch Zusammenfassungen der Änderungen generieren.
SAP hat Joule vorgestellt, einen generativen KI-Assistenten/Copiloten, der für SAP-Cloud-Anwendungen entwickelt wurde. Er basiert auf Geschäftsdaten, unterstützt natürliche Sprache und verfügt über autonome "Agenten"-Funktionen.
Trotz dieser Ankündigungen scheinen die praktischen Anwendungsfälle für KI-spezifische Funktionen in SAP MDG zum Zeitpunkt der Erstellung dieses Beitrags begrenzt zu sein.
Auch wenn KI-Agenten gefördert werden, ist die Autonomie der Agenten (d.h. völlig autonome, entscheidungsbefugte Agenten in MDG) noch etwas eingeschränkt. Zum Beispiel ist die G2 Funktionsliste zeigt, dass für "Agentische KI - Autonome Aufgabenausführung / Mehrstufige Planung / Adaptives Lernen" "Nicht genügend Daten" vorhanden sind.
- Nicht-SAP-Integrationen können komplex und kostspielig werden
Je nach Art des Geschäfts und der Branche sind die Stammdatenanforderungen in jedem Unternehmen stark von der jeweiligen "Datendomäne" abhängig.
Ein Unternehmen mit anlagenintensiven Operationen benötigt zum Beispiel fortschrittliche Datenbereinigungsfunktionen in den Bereichen Material, Anlagevermögen (Ausrüstung) und Zuliefererdaten.
In ähnlicher Weise kann ein "SaaS"- oder "Services"-spezifisches Unternehmen fortgeschrittene Datenbereinigungsfunktionen für "Services" und "Kunden"-Datendomänen benötigen.
Um diese Funktionen aufzubauen und Daten abzurufen, muss ein bidirektionale Synchronisation erforderlich, und das kann bei Nicht-SAP-Systemen ziemlich komplex und teuer sein.
- Individuelle Domainentwicklung ist komplex
SAP MDG bietet eine starke, sofort einsetzbare Unterstützung für wichtige Stammdatenbereiche wie Geschäftspartner, Material und Finanzen.
Wenn Unternehmen jedoch zusätzliche oder branchenspezifische Datendomänen verwalten müssen - z. B. Assets, Projekte, Standorte oder Ausrüstung -, ist die Implementierung oft sehr komplex.
- Eingeschränkte integrierte Datenqualitätsintelligenz
SAP MDG bietet zwar Datenvalidierung und Ableitungsregeln, aber es fehlen fortgeschrittene Datenbereinigungs- oder Abgleichsalgorithmen.
Unternehmen benötigen möglicherweise SAP Data Services (BODS), SAP Information Steward oder Tools von Drittanbietern (wie Informatica oder Trillium), um Daten wirklich zu bereinigen, anzureichern und Duplikate zu erkennen.
Beispiel: Die Erkennung von "doppelten Kunden" mit leichten Namensvariationen kann eine externe Datenqualitätsmaschine erfordern.
Kategorie | Stärken | Beschränkungen |
Integration | Ausgezeichnete Kenntnisse der SAP-Landschaft | Schwach mit Nicht-SAP-Systemen |
Datenverwaltung | Robuste Arbeitsabläufe und Rollen | Kann zu Prozess-Engpässen führen |
Datenqualität | Grundlegende Überprüfungen | Keine erweiterte Reinigung oder KI-Funktionen |
Anpassung | Äußerst flexibel | Kompliziert und zeitaufwendig |
Kosten & Aufwand | Zuverlässigkeit auf Unternehmensniveau | Hohe TCO und Einrichtungszeit |
Benutzererfahrung | Verbessert mit Fiori | Für Gelegenheitsnutzer immer noch komplex |
Bewertungen:
ETL/Datenumwandlungstools
ETL-Software eignet sich hervorragend für die Bereinigung unstrukturierter Daten, vor allem wenn es sich um einmalige Aufgaben handelt, für die es keine trainingsbasierten Frameworks oder Wörterbuchmodifikatoren gibt.
ETL steht einfach für Extrahieren, Transformieren & Laden. Einfach ausgedrückt, extrahiert die Software Daten aus mehreren Drittquellen. Entweder über API-Verbindungen oder direkt in die Software integriert.
Der nächste Schritt ist die Transformation. Zu diesem Zeitpunkt sind das Tabellenschema und die Formate so weit fertiggestellt, dass sie für die weitere Analyse geeignet sind.
Dies ist auch die Phase, in der die Daten bereinigt, angereichert, validiert und dedupliziert werden.
So gut wie alle gängigen ETL-Programme verfügen über eine Art Datenbereinigungsfunktion mit einer benutzerfreundlichen grafischen Oberfläche, die das Bereinigen der Daten ohne großen technischen Aufwand ermöglicht.
Die Bereinigung erfolgt mit einer Vielzahl von Methoden, die meist von Dateningenieuren, Analysten oder Stewards durchgeführt werden.
Einige der verwendeten Techniken werden im Folgenden beschrieben.
1. Verwendung von Formeln des Typs SQL in der GUI -
Formeln wie
SELECT DISTINCT customer_id, email, name FROM customers; kann verwendet werden, um exakt übereinstimmende Duplikate auszusortieren. GROUPBY ist ein weiterer SQL-Ausdruck, der für die Suche nach lückenhaften Ähnlichkeiten in einem Datensatz verwendet wird.
Je nach Umfang der Datenkomplexität können auch fortgeschrittene Fuzzy-Logik-Algorithmen zum Auffinden von Beinahe-Duplikaten verwendet werden.
2. Regeln für die Datenüberprüfung - Datumsformate, numerische Werte, Dropdown-Regeln usw. werden eingerichtet, um Inkonsistenzen zu beseitigen.
3. Umgang mit fehlenden Werten - Null oder fehlende Werte werden ebenfalls markiert und entweder angereichert oder verworfen.
4. Einige ETL-Tools haben auch integrierte Funktionen um externe Datenquellen zum Auffüllen fehlender Felder zu verbinden
5. Standardisierung - Konvertierung von inkonsistenten Formaten in eine Standardkonvention. Zum Beispiel: usd oder USD in $ oder
6. Ausreißer-Validierung - Regeln aufstellen, um Werte zu finden, die weit außerhalb des erwarteten Bereichs liegen. Hier kommt auch bereichsspezifisches Wissen ins Spiel, um Min-Max-Werte festzulegen. Schwellenwerte für Zeichenlängen können für verschiedene Eigenschaften festgelegt werden und Ausreißer können dann überprüft und abgelehnt, angereichert oder einem Workflow hinzugefügt werden.
Laden - Schließlich können die bereinigten und umgewandelten Daten in das Zielsystem geladen werden, z.B. in ein Data Warehouse oder einen Data Lake, wo sie analysiert oder für Berichte verwendet werden können.
Hier sind einige Transformationstools für die Datenbereinigung
AWS Kleber
AWS Glue ist ein vollständig verwalteter ETL-Service, der von Amazon Web Services angeboten wird.
Wir haben ausführlich beschrieben, wie ETL-Tools den gesamten Prozess der Zentralisierung von Daten in einem Data Lake nach der Konsolidierung von Daten aus verschiedenen Quellen automatisieren können.
AWS Glue funktioniert auf ähnliche Weise, indem es Benutzern hilft, Daten vorzubereiten und zwischen verschiedenen Datenspeichern zu verschieben, damit sie für Analysen, maschinelles Lernen und Anwendungsentwicklung genutzt werden können, ohne dass sie Server oder eine komplexe Infrastruktur verwalten müssen.
Neben anderen Aspekten, die weiter unten näher erläutert werden, ist AWS Glue die ideale Wahl für Benutzer, die eine native Integration in Amazons Ökosystem [S3, RDS, Redshift, Athena, Lake Formation, CloudWatch] anstreben.
Im folgenden Video sehen Sie, wie Zoho DataPrep für die Datenbereinigung und -transformation verwendet werden kann:
Was macht AWS Glue so besonders?
- Daten-Profiling: Die Crawler von AWS Glues scannen selbstständig Datenquellen (z.B. S3, RDS, Redshift) usw., um Datenmodelle, Tabellenschemata, Datentypen abzuleiten und mit Formatvarianten (CSV, Parquet) umzugehen. In anderen ETL-Tools wird dies oft manuell durchgeführt.
Profitieren Sie davon: Schnelles Onboarding unordentlicher oder halbstrukturierter Daten mit minimaler manueller Schemadefinition.
- Integrierte Datenqualität und Profiling (Glue Data Quality): Glue enthält jetzt Datenqualitätsfunktionen, mit denen Sie Regeln und Einschränkungen (z.B. "keine Nullen im Primärschlüssel", "Wert zwischen 0-100") definieren und Datensätze automatisch validieren können.
Profitieren Sie davon: Kontinuierliche Überwachung der Datenqualität direkt in den Bereinigungsprozess integriert.
- Code-Flexibilität (Python + Spark): Benutzer können jetzt benutzerdefinierte Bereinigungslogik mit PySpark oder Python-Skripts direkt in Glue Studio schreiben. Glue unterstützt auch benutzerdefinierte Transformationen und ML-basierte Bereinigungen, wie z.B. den Abgleich von Entitäten oder die Erkennung von Ausreißern, mit AWS Glue ML Transforms.
Profitieren Sie davon: Entwickler erhalten sowohl Automatisierung als auch volle Kontrolle für komplexe Bereinigungsszenarien.
- Kosten- und Wartungsvorteile: Da Glue serverlos ist, zahlen Benutzer und Unternehmen nur für die von den Aufträgen genutzte Rechenzeit. Es besteht also keine Notwendigkeit, ETL-Server oder eine Datenbereinigungsinfrastruktur zu unterhalten.
Profitieren Sie davon: Geringere Betriebskosten (Cost of Ownership) für kontinuierliche oder groß angelegte Datenbereinigungsvorgänge.
Einige AWSGlue-Aspekte, auf die Sie achten sollten (mit Workarounds)
Trotz der zahlreichen Vorteile und Vorzüge von AWSGlue ist es wichtig zu verstehen, dass es kein Allheilmittel ist, und das Feedback der Benutzer enthält einige Berichte über mangelhafte Leistung
Latenzzeit beim Auftragsstart
Der Start von Glue-Aufträgen kann 2-5 Minuten dauern, da AWS eine verwaltete Spark-Umgebung hochfahren muss (insbesondere für den ersten Auftrag des Tages).. Dies kann Glue für ETL-Arbeitslasten mit niedriger Latenz oder in Echtzeit ungeeignet machen.
Als Alternative können Benutzer Glue Streaming-Aufträge für Pipelines in nahezu Echtzeit verwenden.
Eine weitere Alternative ist die Ausführung auf einer persistenten Rechenanlage (z.B. AWS EMR ODER Glue for Ray) für Fälle, in denen die Startzeiten kritisch sind.
Schema Drift und komplexe Daten
DynamicFrames sind zwar hilfreich, aber Glue interpretiert Datentypen manchmal falsch (z.B. Ganzzahlen als Strings) oder kann verschachtelte Schemaänderungen nicht korrekt ableiten. Dies bedeutet, dass nachgelagerte Aufträge abbrechen oder inkonsistente Ergebnisse liefern können.
Als Technik zur Schadensbegrenzung kann man
- Validieren Sie die Schema-Inferenz manuell im Glue Data Catalog.
- Verwenden Sie benutzerdefinierte Klassifizierer für nicht standardisierte Dateiformate.
- Implementieren Sie Schema-Versionen und Datenvalidierungsregeln.
Fehlersuche und Beobachtbarkeit
Das Debuggen von Spark-Aufträgen in Glue kann schwierig sein, da die Protokolle in CloudWatch gespeichert werden, aber sie können sehr ausführlich und schwer zu verfolgen sein. Das bedeutet eine langsamere Fehlersuche bei Problemen mit der Transformationslogik oder der Datenqualität.
Als Alternative können Benutzer;
- Verwenden Sie Glue Studio für die visuelle Auftragserstellung und die Vorschau von Daten
- Aktivieren Sie Job-Lesezeichen und Metriken für inkrementelles Debugging
- Verwenden Sie Entwicklungsendpunkte für iterative Tests (auch wenn diese kostspielig sein können).
Bewertungen:
Matillion
Im Gegensatz zu vielen traditionellen Cloud-ETL-Tools, die sich stark auf die Pipeline-Orchestrierung oder entwicklungszentrierte Workflows konzentrieren, positioniert sich Matillion als "Data Productivity Cloud", die Unternehmensteams dabei helfen soll, Pipelines in großem Umfang zu erstellen, zu automatisieren und zu verwalten, ohne dass sie über tiefgreifende Kodierungserfahrung verfügen müssen.
Seine Attraktivität ergibt sich vor allem aus seiner starken Ausrichtung auf moderne Cloud Data Warehouses wie Snowflake, Databricks, Redshift und BigQuery, wo es native Pushdown-Verarbeitung zur Verbesserung der Leistung bietet.
Matillion wurde für Teams entwickelt, die häufig große Datenmengen verschieben, aufbereiten und umwandeln und ein Tool benötigen, das visuelle Workflows mit Erweiterbarkeit verbindet.
Obwohl es sich als Low-Code-Lösung präsentiert, bietet es dennoch genügend Flexibilität für Entwicklungsteams, um Pipelines bei Bedarf mit Python oder SQL anzupassen.
Matillion bietet direkte Integrationen mit über 150 Quellen, darunter Datenbanken, SaaS-Tools, Cloud-Speicher und Nachrichtenströme.
Das folgende Video zeigt, wie die visuelle Leinwand von Matillion verwendet werden kann, um Daten aus mehreren Cloud-Anwendungen in Snowflake zu ziehen und Transformationsschritte per Drag-and-Drop anzuwenden.
Sobald die Daten eingelesen sind, helfen die Transformationskomponenten von Matillion den Benutzern bei der Handhabung von Mapping, Deduplizierung, Validierungsregeln und Anreicherungsschritten. Die meisten dieser Komponenten sind vorgefertigt, was es einfacher macht, einen skalierbaren Datenfluss zusammenzustellen, ohne jeden Schritt manuell skripten zu müssen.
Das Tool unterstützt auch Job-Orchestrierung, Planung, CI/CD und Überwachungs-Dashboards für Teams, die mehrere Pipelines gleichzeitig verwalten.
Einige Fallstricke
Matillion ist zwar ein leistungsstarkes Tool für Cloud-Datenteams, aber es gibt einige Einschränkungen, auf die Benutzer häufig hinweisen:
Ressourcenintensiv für große Transformationen: Da Matillion in hohem Maße auf Pushdowns zu Cloud-Warehouses angewiesen ist, können schlechte SQL-Logik oder nicht optimierte Transformationen zu hohen Warehouse-Rechenkosten führen. Einige Benutzer stellen fest, dass die Leistungsoptimierung zu einer immer wiederkehrenden Aufgabe wird.
Die Lernkurve ist steiler als angekündigt: Obwohl es als Low-Code vermarktet wird, erwähnen viele Benutzer, dass das Verständnis des Cloud Warehouse-Verhaltens, der Job-Abhängigkeiten und der Transformationskomponenten solide SQL-Kenntnisse und praktische Erfahrung erfordert.
Preisliche Bedenken: Bewertungsportale wie G2 erwähnen, dass die verbrauchsabhängigen Preise von Matillion für Unternehmen mit häufigen Pipeline-Aktualisierungen schnell eskalieren können.
Insgesamt eignet sich Matillion am besten für mittlere bis große Unternehmen mit etablierten Cloud Data Warehouses und Teams, die sowohl visuelle Workflows als auch SQL-gesteuerte Optimierungen verwalten können.
Bewertungen:
Zoho DataPrep
Im Gegensatz zu anderen ETL-Tools in dieser Liste wird Zoho DataPrep weithin als "No-Code"-Lösung für die Verbindung und Zusammenstellung von Daten aus verschiedenen Quellen und die Erstellung von ETL-Pipelines schneller durch den Einsatz von GenAI-Modellen.
Zoho ist ein indischer Softwareriese, der mehrere B2B-Softwareprodukte in den Bereichen CRM, Buchhaltung, Workforce Management und Bestandsmanagement anbietet. Man kann also davon ausgehen, dass sie ein oder zwei Dinge über Datenbereinigung wissen, insbesondere bei Kunden- und Bestandsdaten.
Zoho DataPrep verfügt über "Out of the Box"-Integrationen mit über 70 verschiedenen Quellen, um die Rohdaten an einem Ort zusammenzuführen. Dazu gehören Data Warehouses, Unternehmenssoftware, Laufwerksordner und Cloud-Speicher.
Das Video hier zeigt, wie die benutzerfreundliche Drag & Drop-Oberfläche von ZohoDataPrep zum Extrahieren und Zusammenführen von Daten aus den 70 verschiedenen Datenquellen verwendet werden kann.
Die Zusammenführung von zwei Datensätzen kann mit einer der eingebauten Verknüpfungsfunktionen erfolgen. In der Phase "Transformieren" können Validierungs-, Deduplizierungs- und Zusammenführungslogik sowie Anreicherungsschritte angewendet werden.
Sie können die Software zwar als No-Code-Lösung verwenden, doch sind Kenntnisse im Datenmanagement und ein technisches Verständnis für die Verwaltung großer Datensätze Voraussetzung für die Verwendung dieser Datenbereinigungssoftware.
Einige Fallstricke
Es gibt einige Fälle, in denen ZohoDataPrep nicht die ideale Lösung ist.
- Einer der Hauptgründe sind die inhärenten Kapazitätsbeschränkungen. Dies wird in Zoho's eigener "Dokumentation "Beschränkungen. Zum Beispiel ist die maximale #-Spaltenanzahl auf 400 begrenzt, die maximale Größe für den Import aus lokalen und anderen Formaten beträgt 100 MB.
Daher eignet sich die Software nur für kleine bis mittelgroße Daten-Scrubbing-Aufgaben.
- In einigen Benutzerrezensionen aus Quellen wie G2 und dem Community-Portal von Zoho wird erwähnt, dass die Software "fehlerhaft" ist, wenn es um die Verwaltung verschiedener Datentypen geht.
Mehrere Instanzen von Feldern, die mit den Formaten "Datum" oder "Dropdown" importiert wurden, werden als "TEXT" importiert.
Scrub.AI
Scrub.AI unterscheidet sich von herkömmlichen ETL- oder Datenvorbereitungstools, indem es sich speziell auf die automatisierte Datenbereinigung und Qualitätsverbesserung durch KI-gesteuerte Regeln konzentriert.
Während die meisten ETL-Plattformen eine Mischung aus manueller Konfiguration und Regelerstellung erfordern, positioniert sich Scrub.AI als selbstlernendes System, das Probleme mit der Datenqualität im großen Maßstab automatisch erkennt und behebt.
Die Plattform wird vor allem von Teams genutzt, die mit Kunden-, Lieferanten-, Produkt- und Transaktionsdaten arbeiten, bei denen die Beseitigung von Duplikaten, die Standardisierung von Attributen und die Erkennung von Anomalien wichtig sind.
Es verwendet KI-Modelle, die auf branchenspezifischen Datensätzen trainiert wurden, um Felder automatisch zu klassifizieren, Unstimmigkeiten zu erkennen und Korrekturen mit minimalem menschlichem Eingriff zu empfehlen.
Die Plattform lässt sich in verschiedene gängige Datenbanken und Cloud-Anwendungen integrieren und ermöglicht es Benutzern, Flat Files, Tabellenkalkulationen oder API-Streams direkt in einen einheitlichen Arbeitsbereich zu importieren.
Der Reinigungsprozess von Scrub.AI basiert auf automatischer Profilerstellung, KI-basierten Transformationen, Mustererkennung und Anreicherungsschritten.
Das System weist auf doppelte Cluster, fehlende Werte, falsche Formate und inkonsistente Attributstrukturen hin. Benutzer können jede von der KI generierte Empfehlung während der Überprüfungsphase akzeptieren, ablehnen oder ändern.
Einige Fallstricke
Obwohl Scrub.AI Geschwindigkeit und Automatisierung bietet, gibt es Szenarien, in denen die Plattform nicht ausreicht:
Begrenzte Kontrolle über die zugrunde liegende Logik: Power-User berichten manchmal, dass der KI-gesteuerte Ansatz zu viel von dem verbirgt, was das Tool tatsächlich tut. Beim Umgang mit komplexen Datensätzen wünschen sich die Benutzer vielleicht mehr Transparenz oder die Möglichkeit, Annahmen auf Systemebene außer Kraft zu setzen.
Abhängig von den Trainingsdaten: Da sich das Tool in hohem Maße auf vorab trainierte KI-Modelle stützt, variiert seine Genauigkeit je nach Branche. Das Feedback der Community deutet darauf hin, dass die Plattform bei Kunden- oder Anbieterdaten sehr gut abschneidet, aber bei hochtechnischen oder domänenspezifischen Attributen Schwierigkeiten hat.
Nicht ideal für sehr große Dateien oder vollständige ETL-Workflows: Scrub.AI ist in erster Linie eine Datenbereinigungslösung und kein vollständiges Orchestrierungs- oder Pipeline-Tool. Teams, die Scheduling, Versionierung, Stack-weite Integrationen oder Orchestrierung benötigen, müssen es möglicherweise mit anderen Tools kombinieren.
Scrub.AI ist am besten für Unternehmen geeignet, die eine KI-gestützte Verbesserung der Datenqualität benötigen, aber keine vollwertige ETL- oder MDM-Plattform.
Fazit
Bei der Auswahl eines Datenbereinigungstools geht es nicht mehr nur darum, fehlerhafte Datensätze zu korrigieren, sondern eine Datengrundlage zu schaffen, die mit der Geschwindigkeit der heutigen Geschäftsabläufe mithalten kann.
Die richtige Lösung sollte den Teams dabei helfen, von regelmäßigen Bereinigungen zu einem stetigen, zuverlässigen Fluss genauer Informationen überzugehen, der die Planung, die Beschaffung und den täglichen Betrieb unterstützt. Wenn Unternehmen skalieren, wird diese Umstellung unerlässlich.
Ein strukturierter Bereinigungsansatz, der durch intelligente Automatisierung unterstützt wird, stellt sicher, dass die Stammdaten vertrauenswürdig bleiben, reduziert den operativen Aufwand und stärkt letztlich jedes System, das von ihnen abhängt.



