

Das Stammdatenmanagement entwickelt sich von einer reaktiven, regelbasierten Funktion zu einer strategischen, informationsgesteuerten Fähigkeit.
Herkömmliche Ansätze haben oft Schwierigkeiten, mit komplexen, bereichsübergreifenden Daten Schritt zu halten, die über ERP-, CRM-, PLM- und SCM-Systeme verteilt sind, so dass Unternehmen anfällig für Fehler, Duplikate und unvollständige Datensätze sind.
Gartner berichtet, dass schlechte Datenqualität Unternehmen durchschnittlich $12,9 Millionen pro Jahr kostet. KI und maschinelles Lernen verändern diese Landschaft, indem sie autonome Prozesse wie Datenanreicherung, Normalisierung, Deduplizierung und Anomalieerkennung ermöglichen.
Diese Funktionen ermöglichen es Unternehmen, proaktiv hochwertige, konsistente und verwertbare Daten über Kunden-, Produkt- und MRO-Bereiche hinweg zu pflegen.
Durch die Umwandlung von MDM von einer Compliance-gesteuerten Aufgabe in einen proaktiven, KI-gesteuerten Prozess können Unternehmen bisher fragmentierte und fehleranfällige Datensätze in eine einzige Wahrheitsquelle umwandeln und so bessere betriebliche Entscheidungen treffen, Risiken reduzieren und neue Effizienzpotenziale im gesamten Unternehmen erschließen.
VERWENDUNGSFÄLLE
Die Prozesse innerhalb der Stammdatenverwaltung umfassen eine breite Palette von Arbeitsabläufen und Prozessen, für die KI-zentrierte Technologien eingesetzt werden können;
Normalisierung & Standardisierung von Datensätzen
Anreicherung von Stammdatensätzen
Deduplizierung
Integration über Stammdaten-Domänen hinweg
Stammdaten-Governance
In den folgenden Abschnitten erfahren Sie, wie KI-Technologien einige der am häufigsten wiederkehrenden, eintönigen und zeitraubenden Herausforderungen in jedem dieser Bereiche lösen können.
Normalisierung & Standardisierung von Datensätzen
In Unternehmensumgebungen wird ein und derselbe Artikel oft auf verschiedene Weise in verschiedenen Werken, Systemen oder Regionen beschrieben, wobei unterschiedliche Abkürzungen, Namenskonventionen, Maßeinheiten oder sogar Sprachen verwendet werden.
Dies führt zu Inkonsistenzen, die die Analyse, die Durchsuchbarkeit, das Abrufen, die Abgleichslogik und die funktionsübergreifende Zusammenarbeit stören.
Einige der Probleme, die sich aus diesen Herausforderungen ergeben, sind - Schwierigkeiten beim Abgleich von Datensätzen in großen Mengen, Duplizierung aufgrund unterschiedlicher Namenskonventionen und verschiedene Herausforderungen bei der Implementierung eines Data Governance-Programms.
Eine große Herausforderung bei der Stammdatenverwaltung besteht darin, dass wichtige Artikelattribute wie Abmessungen, Druckstufen und Materialqualitäten oft in Freitextbeschreibungen oder technischen Dokumenten wie PDFs, Datenblättern und technischen Handbüchern verborgen sind, Stücklisten (BOMs), oder CAD-Zeichnungen.
Diese unstrukturierte Natur macht es schwierig, diese Datensätze zu extrahieren, zu standardisieren oder auch nur effektiv danach zu suchen. KI und ML, insbesondere Natural Language Processing (NLP), spielen hier eine Schlüsselrolle.
Geschulte NLP-Modelle, die oft Named Entity Recognition (NER) verwenden, können komplexe Beschreibungen analysieren und automatisch Schlüsselattribute identifizieren.
Zum Beispiel, eine Produktbeschreibung wie "SS316 Flansch-Kugelhahn, PN40, DN25" auf intelligente Weise aufgeschlüsselt werden: Material = SS316, Druck = PN40, Größe = DN25, und Typ = Kugelhahn.
Beispiele:
In einem Kundenstammdatensystem verweist die Adresse von Kunde A auf den Staat "Texas" als "TX", während ein anderer Datensatz den Staat einfach als "Texas" bezeichnet. Ähnliche Inkonsistenzen bei Adressen wie "Parkway", die als "Pk way" bezeichnet werden, sind durchaus üblich.
In einem Materialdatensystem kann sich die Abmessung in der Kurzbeschreibung eines Ersatzteils auf die Größe in "Zentimeter" oder "In" oder einfach als ″
Probleme wie diese können zu Überbeständen (im Falle eines Materialstamms), Doppelungen in der Kommunikation (im Falle eines Kundenstamms) und einer ganzen Reihe anderer Probleme führen
Vor der KI wurden diese Herausforderungen mit Hilfe einer Bibliothek bestehender Taxonomien bewältigt, die in der Regel nicht "ganzheitlich" waren, schwer zu pflegen und zu verfolgen, ständige Aktualisierungen erforderten und nur innerhalb einer strukturierten Codebasis verwaltet werden konnten.
Dank KI-Modellen, die "kontextbewusst" sind und auf überprüfbaren, großen Datensätzen trainiert wurden, können diese Ungereimtheiten nun ohne großen Aufwand auf der Grundlage der angenommenen Taxonomie ausgemerzt werden.
Das KI-Modell muss lediglich mit Informationen über die verwendete Taxonomie gefüttert werden und das Modell kümmert sich um die Standardisierungsanforderungen.
Profi-Tipp: Entscheiden Sie sich für eine selbstlernende MDM-Software, die unterwegs von einem "Human-in-the-Loop" geschult werden kann, der die Änderungen überprüft und freigibt.
Auf diese Weise kann das selbstlernende System wirklich autonom werden und die Rolle des Datenverwalters auf die eines Genehmigers beschränken.
1. Abkürzungserweiterung und Terminologiezuordnung: Auf Industriedaten trainierte KI-Modelle verstehen das "Mtr" = "Meter", "SS304" = "Edelstahl 304", "CS Ball Vlv" = "Kugelhahn aus Kohlenstoffstahl", und so weiter. Sie ordnen solche Varianten der standardisierten Terminologie zu.
2. Normalisierung und Umrechnung von Einheiten: Ob Dimensionen geschrieben werden als "10mm", "0.01 m", oder "3IN X 5 YDS"KI kann sie in das bevorzugte Maßsystem (z. B. metrisch) konvertieren und vereinheitlichen und zusammengesetzte Felder in strukturierte Attribute wie Breite und Länge aufteilen.
3. Sprachgnostische Strukturierung: KI-Modelle können nicht-englische Beschreibungen und lokale Formate interpretieren, um globale Konsistenz zu gewährleisten.
Beispiel: Erkennen, dass "Filtros de aceite, 7-1/16 pulg" bezieht sich auf Spanisch auf eine "Ölfilter, 7-1/16 Zoll"und dann korrekt extrahieren und zuordnen.
Anreicherung von Stammdatensätzen
Eines der ärgerlichsten Probleme bei der Verwaltung der meisten Stammdatensätze hat mit fehlenden Informationen zu tun. Dies ist oft das Ergebnis fehlender oder mangelhafter Master Data Governance-Verfahren. Nach Ansicht von Super AGI,
KI-Datenanreicherung kann die Datenqualität um bis zu 90% verbessern und die Verarbeitungszeit um bis zu 80% reduzieren
Fehlende Informationen sind schwierig zu handhaben, da Deduplizierung, Normalisierung und bereichsübergreifende Integrationen problematisch werden, wenn der Kontext eines Datensatzes einfach nicht verfügbar ist.
In der Vergangenheit Anreicherung von Datensätzen erfolgte entweder manuell durch ein Team von Fachleuten ODER durch komplexe Automatisierungen, die eine strukturierte Pflege eines Data Warehouse erforderten.
Gebäude-Automatisierungen bei der Datenanreicherung früher erforderlich Anbieter von Stammdaten-Software Datenpartnerschaften aufzubauen, um auf Lieferantenkataloge, Kontaktdaten, Mitarbeiterinformationen usw. zuzugreifen, je nach der jeweiligen Datendomäne.
Die Beschäftigung eines Teams von Fachleuten ist ein ziemlich teures Unterfangen. Aber auch der Aufwand für die Lösung des Problems der fehlenden Daten steigt, was zu weiteren Verzögerungen führt und die Situation verschlimmert. die Herausforderungen aufgrund schlechter Stammdatenqualität.
Agentische KI-Systeme lösen diese Herausforderung, da sie sowohl "kontextbewusst" als auch in der Lage sind, komplexe Aufgaben wie das Durchsuchen des Internets, das Abrufen von Daten aus Dokumenten und anderen unstrukturierten Quellen und das Füllen von Lücken in den vorhandenen Datensätzen auszuführen.
Außerdem, MCP-Protokolle machen jeden Tag Fortschritte und statten KI-Agenten mit genügend Informationen aus, um sowohl rudimentäre als auch komplexe Arbeitsabläufe mit Hilfe von Software von Drittanbietern ausführen zu können.
Auf diese Weise können zweckmäßig ausgebildete KI-Agenten, wenn sie mit den richtigen Ressourcen ausgestattet sind, fast alle Herausforderungen bei der Datenanreicherung selbstständig und in einem Bruchteil der benötigten Zeit lösen.
Bei gescannten Dokumenten oder technischen Zeichnungen verwenden KI-Systeme die optische Zeichenerkennung (OCR) in Kombination mit der Mustererkennung, um tabellarische Daten oder Spezifikationen zu extrahieren, selbst wenn diese in Bildern oder technischen Layouts erscheinen.
Dies ermöglicht es Organisationen Daten aus technischen Dokumenten extrahieren und verwandeln sie in saubere, strukturierte und durchsuchbare Stammdatensätze.
Einige Anwendungen von KI-Agenten bei der Anreicherung von Stammdaten
Anwendungen
1. Automatisiertes Attribut-Parsing aus Beschreibungen
KI-Modelle, insbesondere NLP-basierte Modelle, die auf branchenspezifischen Datensätzen trainiert wurden, können auf intelligente Weise strukturierte Daten aus komplexen, unstrukturierten Produkt- oder Materialbeschreibungen extrahieren.
Beispiel: Umwandlung von "3-11/16″OD ,7-1/16″LG" in strukturierte Felder wie Äußerer Durchmesser und Länge in Materialstammsätzen.
2. Semantisches Verständnis für Field Mapping
KI versteht den Kontext von Wörtern und Abkürzungen, die in verschiedenen Branchen verwendet werden (z. B. "LG" = Länge, "OD" = Außendurchmesser), und ordnet sie standardisierten Datenfeldern zu.
Beispiel: Erkennen, dass "BALDWIN 915" auf einen Hersteller und eine Teilenummer verweist, und diese entsprechend zuordnen.
3. Harmonisierung und Umrechnung von Einheiten
AI standardisiert verschiedene Formate und Darstellungen von Messungen in ein einheitliches Format für den gesamten Datensatz und beseitigt so Inkonsistenzen.
Beispiel: Konvertierung von "3IN X 5 YDS" in standardisierte metrische Einheiten und Aufteilung in separate Breite und Länge
Fehlende Informationen wie Spezifikationen, Hersteller-Teilenummern oder Maßeinheiten sind ein häufiges Problem, insbesondere bei älteren Datensätzen oder Importen von Dritten.
Diese Lücken können die Arbeitsabläufe in den Bereichen Beschaffung, Compliance und Analyse behindern.
KI und ML bieten intelligente Möglichkeiten, diese Lücken zu füllen. Mithilfe von Techniken wie ähnlichkeitsbasierter Inferenz scannen Modelle vorhandene, vollständige Datensätze, um wahrscheinliche Werte für unvollständige Datensätze vorzuschlagen.
Zum Beispiel, Wenn bei einem neuen Artikel "SKF Bearing 6205" der Außendurchmesser fehlt, kann AI den Wert (z.B. 52mm) von anderen identischen oder ähnlichen Artikeln ableiten, die sich bereits in der Datenbank befinden.
Darüber hinaus kann die generative KI interne Daten mit externen Katalogen oder Lieferantendatenbanken abgleichen, um angereicherte Details wie Abmessungen, Datenblätter, Lebenszyklusdaten oder Ersatzteilvarianten zu erhalten.
Vorhersagemodelle, wie Regressionsalgorithmen oder Entscheidungsbäume, können auch zur Schätzung numerischer Felder wie Spannung, Drehmoment oder Druckwerte verwendet werden, wenn diese nicht explizit erwähnt werden.
Dieses Maß an Anreicherung sorgt für vollständigere und besser nutzbare Stammdaten, minimiert die manuelle Dateneingabe und unterstützt nachgelagerte Automatisierungs-, Beschaffungs- und Compliance-Bemühungen.
Vor allem im Bereich der Kundenstammdaten kommt es häufig vor, dass in einem Datensatz eine E-Mail-Adresse, eine Telefonnummer oder eine Adresse fehlt.
Mit einer Kombination aus MCP-Protokollen und KI-Agenten können diese fehlenden Informationen angereichert werden, indem Daten aus öffentlichen Quellen wie LinkedIn und sogar aus abonnementbasierten Drittquellen wie DnB oder ZoomInfo.
Ein ähnlicher Ansatz wird nun zunehmend auch auf Ersatzteil- und MRO-Daten angewandt, wo fehlende oder inkonsistente Details die Leistung von Wartung und Lieferkette stark beeinträchtigen können.
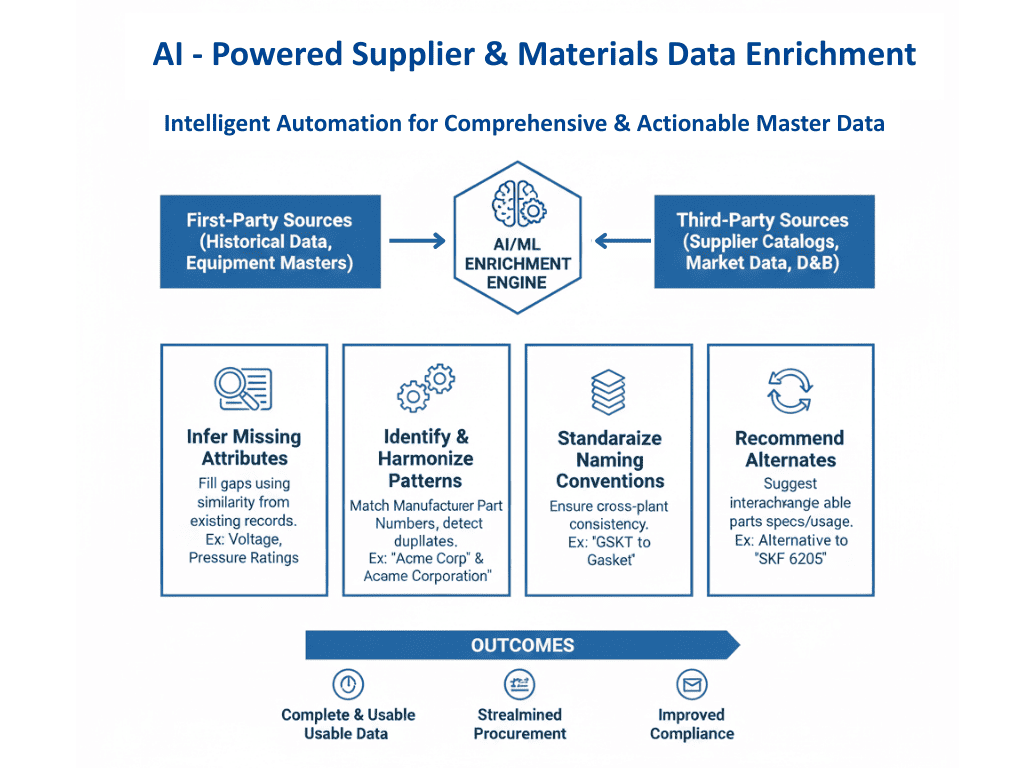
Ersatzteildaten leiden oft unter unvollständigen Beschreibungen, fehlenden technischen Attributen oder doppelten Einträgen, die über mehrere Systeme verteilt sind. Dies führt zu Verwirrung bei der Teilesuche, zu Verzögerungen bei der Wartung und zu redundanter Beschaffung.
Die KI-gestützte Datenanreicherung hilft, diese Herausforderungen zu bewältigen, indem sie die Ersatzteildaten vollständiger, konsistenter und verwertbarer macht.
Durch die Analyse von Ausrüstungsunterlagen, Lieferantenkatalogen und historischen Daten können KI-Systeme:
1. Fehlende Attribute ableiten wie z.B. die Art des Teils, die Materialqualität oder die Betriebsspezifikationen.
Bei Rohmaterialdaten für chemische Anlagen kann KI zum Beispiel durch den Vergleich ähnlicher Materialien in der Datenbank auf fehlende Reinheitsgrade, Gefahrencodes oder Lagerungsanweisungen schließen.
2. Identifizieren Sie Hersteller und Teilenummernmuster für die Harmonisierung zwischen den Anbietern.
In Beschaffungskatalogen kann KI doppelte SKUs erkennen, die unter leicht abweichenden Namen oder Lieferantencodes existieren, und so helfen, redundante Bestellungen zu vermeiden.
3. Benennungskonventionen standardisieren für pflanzenübergreifende Konsistenz.
Zum Beispiel kann KI in Produktstammdaten eine inkonsistente Kategorisierung erkennen, z.B. ein Smartphone, das unter "Zubehör" anstelle von "Mobile Geräte", und korrigieren Sie sie für konsistente Berichte und Analysen.
Gemäß einer Gartner-Bericht,
Bei den Prioritäten der Datenqualitäts-Governance wurde festgestellt, dass Inkonsistenzen zwischen den Silos (mangelnde Konsistenz, Vollständigkeit, Einzigartigkeit der Datensätze) zu den größten Herausforderungen für große Unternehmen gehören.
4. Empfehlen Sie austauschbare oder alternative Teile auf der Grundlage ähnlicher Spezifikationen, Nutzung oder historischer Verbrauchsdaten.
Wenn ein Datensatz zum Beispiel nur "GSKT, 4BOLT, SS316," AI erkennt, dass es sich um eine Dichtung aus rostfreiem Stahl handelt, identifiziert den Flanschtyp und schlägt sogar kompatible Alternativen vor, die auf Lager sind oder von zugelassenen Lieferanten stammen.
Diese erweiterte Ansicht von Ersatzteil- und Produktdaten verbessert die Wartungsplanung, beschleunigt die Beschaffung und ermöglicht eine Bestandsoptimierung, insbesondere in Betrieben mit mehreren Werken, in denen die Sichtbarkeit von Teilen oder die Konsistenz des Produktstamms oft nicht an allen Standorten gegeben ist.
Unten sehen Sie unser Produktvideo, in dem wir Ihnen zeigen, wie unsere agentische Lösung die Daten aus ersten und dritten Quellen anreichert:
Daten-Deduplizierung
Gartner berichtet, dass schlechte Datenqualität Unternehmen durchschnittlich $12,9 Millionen pro Jahr kostet.
Sobald die Datensätze mit Hilfe von KI strukturiert, normalisiert, standardisiert und angereichert wurden, ist die Datendeduplizierung ein Kinderspiel.
Bei der Deduplizierung selbst wird nicht wirklich viel KI eingesetzt (außer bei L2-Duplikaten), aber die vorangehenden Schritte sind der Schlüssel für eine genaue Deduplizierung des gesamten Datensatzes.
Doppelte Einträge in einem Stammdatensatz werden normalerweise in 2 Kategorien eingeteilt - L1 & L2
Die L1-Deduplizierung ist einfach und unkompliziert. In diesem Fall wird der gesamte Datensatz auf der Grundlage einer einzigen Logik de-dupliziert.
Beispiel 1: Dieselbe Material-ID im Falle von direkten Materialien.
Beispiel 2: Dieselbe E-Mail-Adresse oder Telefonnummer im Falle von Kundenstammdaten
Beispiel 3: Dieselbe Hersteller-Partnernummer (MPN) im Falle von MRO-Ersatzteile Daten.
Im Grunde genommen ist jeder Datensatz mit den gleichen Werten in einer Eigenschaft, die den Datensatz unwiderlegbar als doppelten Eintrag identifiziert, ein L1-Duplikat.
Es gibt kaum eine KI, die hier eingesetzt werden kann, da die Logik standardisiert und strukturiert ist.
Aus diesem Grund ist die Anreicherung von Stammdaten in der Regel ein Vorläufer der Stammdaten-Deduplizierung, da durch die Anreicherung mehrere Werte im System aktualisiert werden können, die dann für die L1-Deduplizierung genutzt werden können.
L2-Duplikate hingegen sind weitaus komplexer und werden in der Regel verwendet, wenn die für die Anwendung der L1-Logik erforderlichen Werte einfach nicht vorhanden sind.
Die KI ist einfach noch nicht weit genug entwickelt, um die Erkennung von L2-Duplikaten vollständig zu automatisieren.
KI kann die Arbeit jedoch erheblich vereinfachen, indem sie den gesamten Datensatz und den Datensatz selbst auf wahrscheinliche Duplikate überprüft, bevor sie einen "Konfidenzniveau duplizieren"die dann als Aufgabe einem menschlichen Prüfer zugewiesen werden kann, um die Datensätze entweder als Duplikate zu akzeptieren oder abzulehnen.
Nachdem der Data Steward "akzeptiert" hat, werden die Datensätze in der Regel zusammengeführt, wobei die Daten aus den 2und Datensatz wird gelöscht, nachdem die Felder im 1. Datensatz erstellt wurden.
Unten sehen Sie ein Video, das zeigt, wie unser KI-Agent die Daten dedupliziert:
Stammdatenintegration für den Erfolg in mehreren Bereichen
Einer der bekanntesten Kritikpunkte an einem Stammdatensystem ist die Tatsache, dass jeder Stammdatensatz in der Praxis isoliert von den anderen in unterschiedlichen Organisationssystemen existiert.
Um die Leistung einer bestimmten organisatorischen Funktion wirklich zu verstehen, ist die Interpretation von Daten über Stammdatenbereiche hinweg entscheidend.
Beispiel 1: Es ist wichtig zu wissen, wie viele Kunden über einen bestimmten Marketing-Kommunikationskanal erreicht werden können, aber es ist auch wichtig zu wissen, welche Produkte diese Verbraucher am meisten bevorzugen. Dies erfordert tiefe Integrationen mit Produktstammdaten
Beispiel 2: Es ist wichtig zu wissen, wie viele Ersatzteile in der Beschaffungsplattform für die Bereitstellung von Produktionsaktivitäten vorhanden sind. Noch wichtiger ist es jedoch zu wissen, welche dieser Teile für die Instandhaltung kritischer Anlagen benötigt werden. die wichtigen Ersatzteile.
Dies ist nur mit einer tiefen Integration von Anlagenstammdaten mit dem Ersatzteilmaterialstamm möglich.
Datenverwaltung
Stammdaten-Governance Frameworks sollen sicherstellen, dass die Stammdaten korrekt, sicher und standardisiert sind und mit internen Richtlinien und externen Vorschriften übereinstimmen.
Da jedoch die Datenmengen wachsen und über verteilte Systeme (ERP, PLM, CRM, SCM usw.) hinweg immer komplexer werden, ist die manuelle Durchsetzung von Governance-Richtlinien nicht mehr skalierbar und reaktiv.
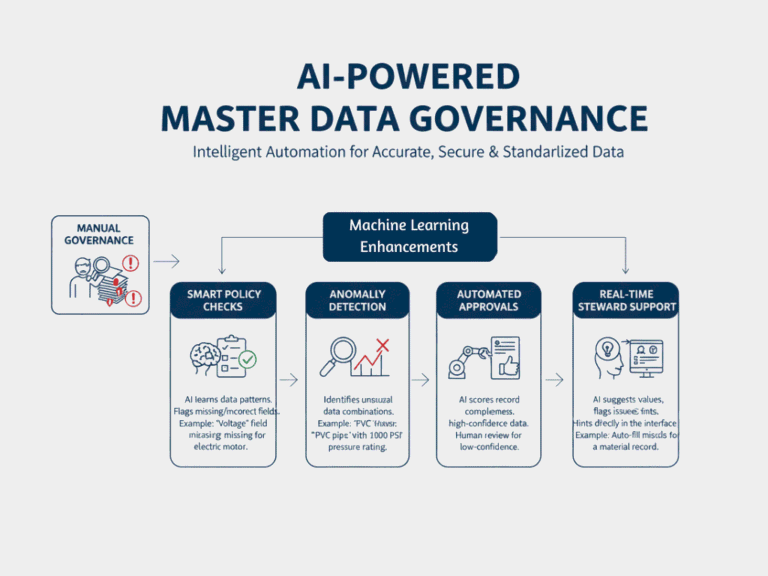
Maschinelles Lernen bringt proaktive, intelligente Automatisierung in die Kernfunktionen der Data Governance, indem es die dynamische Durchsetzung von Richtlinien, die Erkennung von Anomalien und intelligente Entscheidungshilfen ermöglicht.
Diese Modelle können die Datenqualität kontinuierlich überwachen und verbessern und gleichzeitig den manuellen Aufwand für die Datenverwalter verringern.
Anwendungen:
1. Intelligente Richtlinienkontrollen
Die KI lernt, wie saubere, genehmigte Datensätze normalerweise aussehen, und überprüft neue Einträge auf fehlende oder falsche Felder, auch wenn es keine feste Regel gibt.
Beispiel: Wenn in den meisten Datensätzen für Elektromotoren das Feld "Spannung" ausgefüllt ist und in einem neuen Datensatz nicht, wird dies von AI sofort angezeigt.
Die KI schaut sich frühere Datensätze an, lernt, welche Felder zusammengehören, und nutzt dieses Wissen, um Fehler zu erkennen.
2. Erkennen von Anomalien und Fehlern
ML-Modelle erkennen ungewöhnliche Werte oder Kombinationen in Ihren Daten, die nicht in normale Muster passen.
Beispiel: Ein "PVC-Rohr", das mit "1000 PSI" angegeben ist, wird markiert, weil PVC normalerweise nicht so viel Druck aushält.
KI entwickelt ein Gespür dafür, was für jeden Artikeltyp normal ist und fängt Ausreißer mithilfe von Mustererkennungsmodellen wie Isolation Forest oder Autoencodern ab.
3. Automatisierte Datensatzgenehmigungen
Die KI bewertet neue oder aktualisierte Datensätze danach, wie sauber und vollständig sie sind. Datensätze, die eine hohe Zuverlässigkeit aufweisen, können automatisch genehmigt werden, während Datensätze, die eine geringere Zuverlässigkeit aufweisen, zur Überprüfung an einen Mitarbeiter geschickt werden.
Beispiel: Ein als "Hex Bolt" klassifizierter Artikel, bei dem alle Felder korrekt ausgefüllt sind und mit den Daten aus der Vergangenheit übereinstimmen, wird automatisch genehmigt.
ML-Modelle berechnen einen Konfidenzwert, der darauf basiert, wie gut der Datensatz mit bestehenden Standards übereinstimmt.
4. Hilfe für Data Stewards in Echtzeit
KI unterstützt Datenverwalter bei ihrer Arbeit, indem sie Werte vorschlägt, auf fehlende Felder hinweist oder mögliche Probleme aufzeigt.
Beispiel: Bei der Überprüfung eines Materialdatensatzes sieht ein Verwalter KI-Vorschläge für fehlende Felder und erhält Warnungen, wenn etwas nicht mit ähnlichen Einträgen übereinstimmt.
NLP- und ML-Modelle laufen im Hintergrund und zeigen intelligente Hinweise und Warnungen direkt auf der Benutzeroberfläche an.
Im Folgenden finden Sie einige Anwendungsfälle:
Kundenstammdaten:
In großen, multinationalen Unternehmen kommen neue Kundendatensätze oft über mehrere Kanäle, CRM-Portale, von Partnern eingereichte Daten oder interne Uploads.
Fehlende E-Mail-Adressen, Steuer-IDs oder unvollständige Rechnungsinformationen können die Rechnungsstellung verzögern und Risiken für die Einhaltung von Vorschriften bergen. KI-Governance-Systeme erkennen automatisch fehlende Pflichtfelder, reichern sie anhand verifizierter interner und externer Quellen an und markieren wahrscheinliche Duplikate am Eingabepunkt.
Zum Beispiel, Wenn zwei Datensätze "Acme Corp" und "Acme Corporation" enthalten, markiert das System eine mögliche Dublette und verhindert redundante Einträge. Dies gewährleistet hohehochwertige Kundendaten bei gleichzeitiger Reduzierung des manuellen Aufwands.
Material- und Ersatzteildaten:
Im Bereich Materialien oder MRO fehlen häufig Spezifikationen, Teilenummern der Hersteller oder Maßeinheiten, insbesondere bei älteren Datensätzen oder Importen von Drittanbietern.
Diese Lücken behindern die Beschaffung, die Wartungsplanung und die Analyse-Workflows. KI-gesteuerte Anreicherung kann fehlende Werte aus vorhandenen Datensätzen ableiten, Querverweise auf Lieferantenkataloge herstellen und Namenskonventionen über mehrere Werke hinweg standardisieren.
Zum Beispiel, ein neuer Datensatz "SKF Bearing 6205", dem der Außendurchmesser fehlt, kann automatisch mit dem richtigen Wert aus ähnlichen Artikeln in der Datenbank angereichert werden.
Ebenso kann ein Datensatz, der als "GSKT, 4 SCHRAUBEN, SS316" kann erweitert werden, um eine Dichtung aus rostfreiem Stahl anzugeben, den Flanschtyp zu identifizieren und kompatible Alternativen vorzuschlagen.
Vorhersagemodelle wie Regressionsalgorithmen oder Entscheidungsbäume können auch numerische Felder wie Spannung, Drehmoment oder Druckwerte schätzen, wenn keine expliziten Werte vorliegen.
Durch die Identifizierung von Anomalien, die Harmonisierung von Teilenummern, die Standardisierung von Beschreibungen und das Vorschlagen von Alternativen sorgt die KI dafür, dass der Materialstamm zu einer zuverlässigen, umsetzbaren Quelle der Wahrheit wird.
Unten sehen Sie unser Video zur Data Governance-Lösung von Verdantis:
Entwurf und Einsatz von KI in MDM
Die Vorteile des maschinellen Lernens in der Stammdatenverwaltung liegen auf der Hand, aber eine erfolgreiche Einführung erfordert eine durchdachte Integration in die Unternehmensarchitektur und die Governance-Modelle:
Qualität der Trainingsdaten: Die Leistung von KI/ML-Modellen hängt direkt von der Qualität und Repräsentativität der historischen Daten ab, die zum Trainieren der Modelle verwendet werden.
Domänenspezifischer Kontext: Modelle von der Stange müssen oft angepasst oder umgeschult werden, um die domänenspezifischen Nuancen in Konstruktions-, Fertigungs- oder Beschaffungsdaten zu verarbeiten.
Erklärbarkeit und Vertrauen: Die Benutzer müssen nachvollziehen können, wie die KI zu einer bestimmten Entscheidung oder einem Vorschlag gekommen ist, insbesondere in regulierten Branchen.
Mensch-im-Schleifen-Modus (HITL): KI-Systeme sollten so konzipiert sein, dass sie die Datenverwalter ergänzen und nicht ersetzen, so dass bei Bedarf eine menschliche Aufsicht möglich ist und Feedbackschleifen zur kontinuierlichen Verbesserung geschaffen werden.
Fazit
KI und ML verbessern nicht nur das Stammdatenmanagement, sondern sie definieren das Mögliche neu. Diese Technologien bieten ein Maß an Geschwindigkeit, Anpassungsfähigkeit und Intelligenz, das manuelle und regelbasierte Systeme nicht erreichen können.
Für MDM, MRO-Datenmanagement und Data Governance ist KI kein neues Konzept mehr, sondern eine notwendige Fähigkeit, um die Datenqualität zu verbessern, die Entscheidungsfindung zu beschleunigen und den Unternehmensbetrieb zukunftssicher zu machen.
Im Zuge der digitalen Transformation sind Unternehmen, die KI-gestützte Intelligenz in ihre Stammdatenverfahren einbinden, besser positioniert, um mit Agilität, Präzision und Einblick zu arbeiten.



