

Todas las operaciones con un uso intensivo de activos aplican el mismo conjunto de estrategias de mantenimiento. Se clasifica el orden de las órdenes de trabajo. Se mantiene un stock de reserva. Se preparan los kits de piezas de repuesto. Se racionaliza el excedente. Se evalúa a los proveedores.
Lo que varía de una operación a otra no es qué estrategias se están aplicando, sino el nivel de madurez al que se aplica cada una.
Algunas plantas clasifican las órdenes de trabajo basándose en su intuición y en el método FIFO. Otras tienen códigos de prioridad integrados en el sistema de gestión de mantenimiento (CMMS). Un número más reducido cuenta con una clasificación basada en la inteligencia artificial y ponderada por nivel de criticidad, que se recalcula a partir de datos de producción en tiempo real. Técnicamente, las tres aplican la misma estrategia. Sin embargo, en la práctica, se trata de operaciones muy diferentes.
En este artículo se analizan once de esas estrategias, ordenadas según la cadena operativa (decidir qué es lo importante, planificar en torno a ello, ejecutarlo y ajustar el ciclo), y se clasifica cada una de ellas en tres niveles de madurez operativa.
Hojas de cálculo, conocimientos implícitos, decisiones basadas en la personalidad y en la escalada de problemas. Puntos de reabastecimiento establecidos en un taller y congelados en Excel. La criticidad se trata como un ejercicio de coordinación puntual. Funciona a pequeña escala, pero se desmorona a escala de red de plantas.
Los módulos de CMMS, ERP y EAM recogen el flujo de trabajo. Existen códigos de prioridad, niveles mínimos y máximos y registros de activos. Sin embargo, la lógica subyacente es estática: se configura una vez y rara vez se revisa. El sistema es un registro, no una capa de apoyo a la toma de decisiones.
Los datos en tiempo real proceden de sistemas ERP, EAM y sensores del IIoT. Los agentes de IA se encargan del trabajo pesado (puntuación, análisis, clasificación y emparejamiento), y los expertos humanos intervienen para anular las decisiones cuando lo consideran oportuno. Esta intervención sirve para entrenar la siguiente decisión. La evaluación de la criticidad es continua, la preparación de kits se basa en las órdenes de trabajo y los cálculos de reposición son dinámicos.

La criticidad es el hilo conductor que une las once etapas. El paso de lo «sistematizado» a lo «inteligente» supone casi siempre el paso de una criticidad estática a una criticidad viva.
A continuación se detallan las distintas estrategias, la fase de madurez en la que se sitúan, el problema general que resuelven y cómo el software adecuado (junto con la disciplina funcional que lo sustenta) les permite avanzar en la escala.
Nivel 1: El nivel de decisión
Las dos primeras estrategias determinan lo que es importante. Todo lo que viene después se basa en estas decisiones, por lo que, cuando son erróneas, la mala racha se extiende.
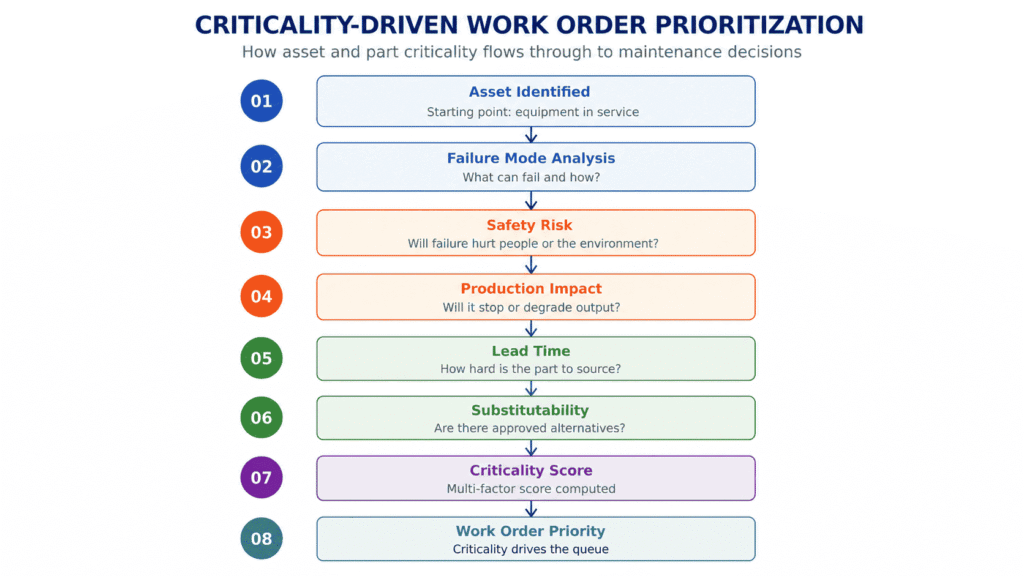
1. Priorización de órdenes de trabajo basada en la criticidad
El flujo de trabajo. Las órdenes de trabajo abiertas se incorporan a una cola y esta se clasifica. Los trabajos que tienen mayores repercusiones en la seguridad, la producción o el cumplimiento normativo reciben mano de obra y piezas con prioridad sobre los trabajos rutinarios.
Donde se rompe. El orden de prioridad se decide por intuición, por el orden de llegada o por quién tenga la voz más fuerte esa mañana. Una junta con fugas en un compresor esencial pasa a estar en segundo plano respecto a una reparación de la iluminación en el comedor, ya que ambas llegaron al mismo tiempo.
El problema principal es el desperdicio de recursos en tareas innecesarias. Los equipos de mantenimiento rara vez están inactivos; por lo general, se dedican a tareas que no son prioritarias. Cada hora dedicada a tareas de poca importancia es una hora que se resta a una tarea que realmente pone en riesgo la producción.
La solución asistida por software. Una puntuación de criticidad, calculada en función de la seguridad, el impacto en la producción, el plazo de entrega y la sustituibilidad, determina una clasificación objetiva por orden de prioridad. El agente de IA expone los argumentos que justifican cada clasificación. El planificador aprueba o anula la decisión, adjuntando una justificación, y dicha anulación sirve para entrenar al modelo. Aquí es donde evaluación de la criticidad de los activos deja de ser un taller que se celebra una vez al año y se convierte en una herramienta de apoyo a la toma de decisiones diaria.
2. Análisis de la criticidad a nivel de activos y de componentes
El flujo de trabajo. Los activos, y los componentes que los integran, se clasifican en función del impacto que tendría su fallo en el funcionamiento.
Donde se rompe. La mayoría de las plantas llevan a cabo el análisis de criticidad como un ejercicio de alineación puntual, impulsado por un responsable de fiabilidad con la colaboración de varios equipos. El resultado es un registro estático que queda obsoleto en cuestión de meses. Y lo que es peor, casi todas las implementaciones parten de un supuesto tácito que no resiste el contacto con la realidad.
El error fatal
La noción convencional de «criticidad» parte de la base de que todas las piezas de un activo crítico son, a su vez, críticas, y que las piezas de los activos no críticos no lo son. En la práctica, ambas partes de esa afirmación son erróneas. Una sola junta de bajo coste puede dejar fuera de servicio un compresor de primer nivel. Un cojinete de alto valor puede encontrarse en un activo cuyo fallo no tenga ningún impacto en la producción porque hay una unidad redundante justo al lado.
La solución asistida por software. La evaluación multimodelo (FMECA, VED, ABC), combinada con datos propios de ERP y EAM, junto con el entrenamiento en patrones de fallo específicos del sector, permite determinar la verdadera criticidad a nivel de pieza. Este es el tipo de cálculo que ningún ser humano puede realizar a gran escala.
La disciplina funcional es tan importante como el modelo. Un experto en la materia revisa la puntuación, puede anularla si lo justifica, y ese aprendizaje se extiende a toda la red de la planta. La capa a nivel de pieza es la que garantiza la fiabilidad de las estrategias posteriores (preparación de kits, puntos de reabastecimiento, desencadenantes predictivos).
Puedes obtener más información sobre los mecanismos subyacentes en puntuación de la criticidad a nivel de pieza y cómo se relaciona con Buenas prácticas de FMEA y FMECA.
Nivel 2: El nivel de planificación
Una vez evaluada la criticidad, la planificación dispone de una base sólida sobre la que trabajar. Las tres estrategias siguientes convierten esa información en piezas preparadas, niveles de stock dinámicos y datos fiables. Es aquí donde se genera o se evita la mayor parte del desperdicio operativo.
3. Preparación de lotes de existencias
El flujo de trabajo. Todas las piezas necesarias para un trabajo se seleccionan y se preparan en un kit antes de que el técnico recoja la orden de trabajo.
Donde se rompe. El técnico llega al lugar de trabajo y se da cuenta de que falta una pieza, que el tamaño no es el adecuado o que ya se ha asignado a otra orden de trabajo. El tiempo de trabajo se va esfumando en idas y venidas al almacén. En las plantas con una alta tasa de utilización, la diferencia entre la hora de inicio prevista y la hora de inicio real puede llegar a ser de varias horas por trabajo.
El problema principal es el tiempo de inactividad que nadie había previsto. Técnicamente, se dispone de los recursos necesarios para el trabajo. Técnicamente, las piezas están en el almacén. Técnicamente, la orden de trabajo está abierta. Y, sin embargo, la producción está a la espera porque esos tres aspectos técnicos no coinciden en la línea de montaje.
Por qué falla la preparación de kits
Las listas de preparación se generan con retraso, las piezas se identifican erróneamente debido a la duplicación de referencias, los kits se preparan sin comprobar el stock real y no se proponen alternativas cuando falta la pieza principal. El técnico se da cuenta de ello una vez en el lugar de trabajo, no en el almacén.
Cómo se mantiene el kitting
El sistema lee la orden de trabajo, selecciona las piezas necesarias mediante una vinculación precisa con la lista de materiales, comprueba la disponibilidad con el stock en tiempo real, muestra los sustitutos aprobados y confirma la ubicación física antes de programar el trabajo. El kit se prepara antes de que llegue el técnico.
La solución asistida por software. La preparación de kits solo funciona si el registro de inventario es preciso, la vinculación con la lista de materiales es efectiva y el sistema sabe dónde se encuentra físicamente cada pieza en las distintas plantas. Aquí es donde optimización del inventario de piezas de repuesto cumple con su cometido. La pieza tiene que poder localizarse, hay que analizar la lista de materiales y el stock real tiene que ser fiable.
MRO360 compara la orden de trabajo con la lista de materiales del activo, comprueba la disponibilidad de las piezas en el módulo de inventario y prepara el kit. La disciplina de Software de gestión de inventario para MRO No se trata tanto de una IA sofisticada como de considerar el almacén como parte de la orden de trabajo, y no como un problema aparte.
4. Configuración del punto de reabastecimiento y del stock de seguridad
El flujo de trabajo. Cada artículo cuenta con un indicador de reposición y un margen de seguridad diseñado para absorber las fluctuaciones de la demanda durante el periodo de reposición.
Donde se rompe. Los niveles mínimos y máximos se fijaron en un taller hace años y nadie los ha revisado desde entonces. A los repuestos críticos se les aplica la misma lógica de reservas que a los consumibles básicos. El resultado es lo peor de ambos mundos: falta de existencias de las piezas importantes y exceso de existencias de las que no lo son.
El problema fundamental es que el sistema de reordenación estática te penaliza por partida doble. Inmoviliza el capital circulante en piezas que nunca vas a necesitar y te deja en una situación vulnerable en cuanto a las piezas que no puedes permitirte que te falten. Ambos son costes ocultos hasta que un activo de primer nivel deja de funcionar por una pieza que, técnicamente, estaba «dentro de la política».
El cálculo de los pedidos de reposición
Punto de reabastecimiento = (Consumo medio diario × Plazo de entrega) + Stock de seguridad. La fórmula es correcta. El problema están en los datos de entrada. El consumo varía en función del volumen de producción. El plazo de entrega varía en función del rendimiento del proveedor. El stock de seguridad varía en función de la tolerancia al riesgo. Cuando los datos de entrada están desactualizados, el resultado es erróneo en ambos sentidos.

La solución asistida por software. Cálculo dinámico del punto de reabastecimiento significa que los datos se obtienen en tiempo real: el consumo real del módulo de inventario, los plazos de entrega reales del historial de proveedores y un stock de seguridad ponderado por criticidad que actúa como colchón de forma agresiva para los repuestos de primer nivel y de forma conservadora para los repuestos básicos.
MRO360 también cierra el ciclo cuando el stock de una pieza cae por debajo del umbral. El sistema señala la falta de stock, recomienda una solicitud de compra o sugiere una transferencia de stock entre plantas cuando la pieza se encuentra sin utilizar en otra ubicación. Los cálculos son fiables porque los datos que los alimentan son en tiempo real, y la acción se vuelve sistemática porque el sistema no espera a que alguien se dé cuenta.
5. Datos maestros de piezas de repuesto y vinculación con la lista de materiales
El flujo de trabajo. Cada registro de pieza está limpio, sin duplicados, correctamente clasificado y vinculado con precisión a los activos a los que pertenece.
Donde se rompe. El mismo artículo aparece con cuatro descripciones diferentes, dos de ellas con errores ortográficos. Tres de esos registros indican que no hay existencias y uno indica que hay excedentes, pero el planificador no sabe cuál es el correcto. La lista de materiales del activo en el EAM está incompleta, por lo que, aunque se encuentre la pieza, el planificador no puede estar seguro de que sea la adecuada.
El problema fundamental es que todas las estrategias posteriores a esta dan por sentado, sin decirlo, que los datos están limpios. La puntuación de criticidad requiere una identificación fiable de las piezas. La preparación de kits necesita una vinculación precisa con la lista de materiales. Los cálculos para la reposición requieren un historial de consumo sin duplicados. Cuando la base está contaminada, todas las estrategias posteriores heredan esa contaminación, por muy sofisticados que sean los análisis que se apliquen sobre ella.
La solución asistida por software. Aquí es donde el gestión de datos maestros para el mantenimiento Esta capa se gana su lugar. La normalización automatizada elimina los registros duplicados del sistema heredado. El enriquecimiento basado en agentes completa los atributos que faltan mediante el análisis de catálogos de fabricantes de equipos originales y documentos de listas de materiales de activos. La coincidencia semántica reconoce que «BRG 6205 ZZ» y «Rodamiento de ranura profunda 6205-2Z» son la misma pieza física.
La suite MDM Módulo Harmonize limpia el legado y el Módulo de integridad se aplica a cada nuevo registro en el momento de su creación, para que la base de datos no vuelva a deteriorarse. A continuación, MRO360 se encarga de la capa de vinculación de la lista de materiales (BOM), analizando de forma autónoma los documentos de la lista de materiales de los activos para establecer relaciones precisas entre las piezas y los equipos.
Esta es la base, no un simple complemento. Considérala como el pilar que da credibilidad a todas las estrategias que la preceden y la siguen. Encontrarás más detalles sobre el enfoque subyacente en nuestros artículos sobre cómo limpiar los datos de las piezas de recambio y Taxonomía de datos de MRO.

Catálogos en hojas de cálculo, conocimientos implícitos, registros duplicados de los que nadie se hace responsable. Las listas de materiales (BOM) se guardan en archivos PDF en unidades compartidas.
Maestro de materiales del ERP con deduplicación basada en reglas. Proyectos de limpieza periódicos. Listas de materiales cargadas, pero que rara vez se vinculan al inventario real.
Enriquecimiento de agentes, correspondencia semántica, análisis autónomo de listas de materiales y gobernanza continua mediante flujos de trabajo de Integrity.
Analice con nuestro equipo sus datos actuales de mantenimiento, la integración de la lista de materiales y la situación de sus existencias. Compararemos sus once estrategias con el modelo de madurez y con sus propios registros, y le mostraremos en qué aspectos MRO360 y la suite MDM podrían marcar la diferencia.
Verdantis se enorgullece de ser el socio de confianza de organizaciones líderes en todo el mundo.
Desde empresas de Fortune 500 hasta pioneras del sector, nuestros clientes han confiado en nuestras soluciones MDM






Capa 3: La capa de ejecución
La toma de decisiones y la planificación dan paso a la ejecución. Es aquí donde los datos depurados, el kit, la puntuación de criticidad y la señal predictiva se unen en el activo, o bien no lo hacen.
6. Planificación de órdenes de trabajo
El flujo de trabajo. Los trabajos se programan teniendo en cuenta tres factores a la vez: la disponibilidad de mano de obra, la disponibilidad de piezas y la ventana de producción o de los activos.
Donde se rompe. Los trabajos se programan sin confirmar si se dispone de las piezas necesarias o sin conocer el margen de disponibilidad de los activos por parte del departamento de operaciones. Los equipos se encuentran con una línea en funcionamiento que no se puede parar, o con una pieza que aún está en tránsito. Los trabajos planificados y los imprevistos entran en conflicto y el planificador tiene que reorganizarlo todo en tiempo real.
El problema principal es que la planificación es el punto más vulnerable del mantenimiento. Cuando un equipo no puede seguir adelante, tres equipos se enteran en menos de una hora, y la confianza en planificación del mantenimiento se extiende por toda la planta.
La solución asistida por software. Una planificación que tiene en cuenta las restricciones, que comprueba la disponibilidad de las piezas en relación con la capa de preparación de kits, equilibra la demanda planificada y la no planificada, y se ajusta al estado actual de los activos. La disciplina que subyace a este proceso es la misma que en el control del tráfico aéreo: el sistema no da luz verde a un trabajo a menos que las tres restricciones se cumplan simultáneamente.
7. Activación predictiva de órdenes de trabajo
El flujo de trabajo. Una señal de estado procedente del IIoT o del SCADA genera una orden de trabajo antes de que el activo falle, no después.
Donde se rompe. Los datos de los sensores se recopilan, a veces con un gran coste, pero no están integrados en los procesos de mantenimiento y gestión de inventario. Una anomalía en las vibraciones activa una alerta en el control de estado en el panel de control, pero no crea una orden de trabajo, no activa la preposición de piezas y no actualiza los cálculos de reposición. Se produce la avería prevista, pero no se prepara ninguna pieza de repuesto.
El problema fundamental es que el mantenimiento predictivo tiene un límite en cuanto al retorno de la inversión, a menos que la información se integre en los procesos de gestión de inventario y ejecución. Una avería prevista correctamente para la que no hay piezas disponibles en stock sigue siendo una falta de existencias.
La señal se detiene aquí
Los datos del sensor indican una anomalía. Un ingeniero de fiabilidad la detecta en un panel de control. El sistema de mantenimiento, el sistema de inventario y el portal de proveedores no la detectan.
La señal pasa
La anomalía genera una orden de trabajo con un modo de fallo previsto, identifica las piezas que probablemente fallarán y las prepara de antemano a través de las capas de preparación de kits y reposición. La ejecución está lista antes de que se produzca el fallo.
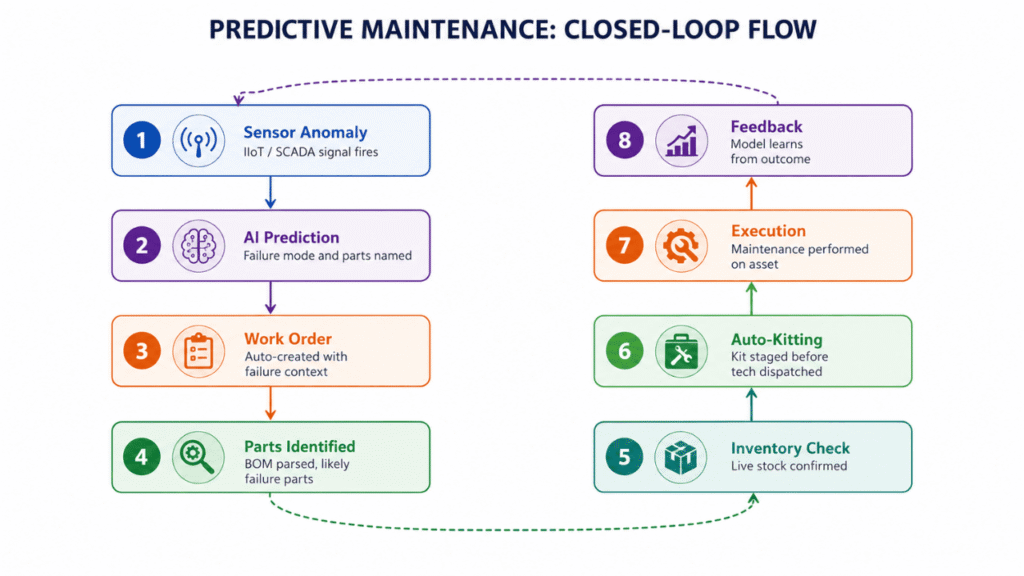
La solución asistida por software. Los datos de los sensores alimentan un modelo de predicción de averías que identifica las piezas que podrían fallar. Esas piezas se preparan mediante el flujo de trabajo de preparación de kits y se tienen en cuenta en el cálculo de la reposición. Hay más información sobre lo que el capa de datos de mantenimiento predictivo cómo tendría que ser en realidad para que esto sea viable, y en el mantenimiento preventivo frente a mantenimiento predictivo una distinción que, en la práctica, suele difuminarse.
Este es uno de los ejemplos más claros de cómo los agentes de IA y los expertos en la materia pueden trabajar en conjunto. El modelo identifica las piezas que probablemente fallarán. El ingeniero de fiabilidad valida la predicción. El planificador de mantenimiento prepara el kit con antelación. Ninguno de ellos realiza el trabajo de los demás.
Capa 4: La capa de optimización
Las tres primeras capas se encargan de la gestión operativa. La cuarta se encarga de optimizarla. Estas son las estrategias que permiten localizar el capital circulante atrapado en tu almacén, las oportunidades de sustitución ocultas en tu catálogo, los patrones de proveedores que se esconden en tu historial de compras y el excedente que se encuentra a ochenta kilómetros de agotarse.
8. Racionalización de existencias obsoletas y excedentes
El flujo de trabajo. El inventario se revisa periódicamente para identificar las piezas que no se han vendido y que probablemente no convenga mantener en stock.
Donde se rompe. La revisión es esporádica y suele ponerse en marcha a raíz de una pregunta del director financiero, más que como parte de un proceso. Las piezas que llevan años sin utilizarse siguen en el almacén porque nadie sabe a ciencia cierta si se trata de repuestos esenciales, de modelos obsoletos o si simplemente se han olvidado.
El problema del 25 %
Los estudios del sector sitúan sistemáticamente el stock muerto en torno a una cuarta parte del inventario total de MRO. Eso supone capital circulante, espacio de almacén, costes de seguros y riesgo de auditoría asociados a piezas que nunca se utilizarán. En una red de plantas que gestiona un inventario de MRO valorado en decenas de millones de dólares, el coste es considerable.
La solución asistida por software. La clasificación continua de movimientos (rápido, lento, inactivo) señala el excedente y piezas de repuesto obsoletas a medida que se acumulan, y no al final del año. El sistema recomienda la medida adecuada: devolver al proveedor, liquidar para su reciclaje o transferir a otra planta que esté utilizando activamente esa pieza.
El problema general que esto resuelve es la «inercia silenciosa del capital». Nadie se da cuenta de una pieza que no se ha movido. El sistema es el que debe estar atento, con avisos que lleguen a las personas que pueden actuar. El Análisis de gastos MRO Es en este nivel donde el tema pasa a ser una cuestión que compete a la junta directiva.
9. Estandarización y sustitución de piezas de repuesto
El flujo de trabajo. Las piezas intercambiables se agrupan en una ficha estándar. Las piezas sustitutivas viables se identifican y se almacenan juntas, de modo que la falta de existencias de una de ellas no paralice un trabajo que otra pieza pueda completar.
Donde se rompe. La misma pieza física figura bajo varias referencias porque tres fabricantes de equipos originales distintos la suministran con tres códigos diferentes, y un cuarto código procede de una adquisición. En las estanterías hay alternativas funcionalmente idénticas, pero el planificador no puede verlas porque no están vinculadas.
El problema principal es el exceso de pedidos provocado por un inventario invisible. El producto sustitutivo está en stock. El sistema indica que no. La planta pide el producto original de todos modos y acaba pagando por dos piezas que cumplen la misma función.
La solución asistida por software. La coincidencia semántica y la inteligencia de sustituibilidad permiten identificar equivalentes funcionales entre catálogos, fabricantes de equipos originales y datos de compras. El modelo utiliza el mismo tipo de clasificación de las piezas de recambio y el trabajo de taxonomía que sustenta la capa de gestión de datos maestros (MDM), pero aplicado a la interoperabilidad en lugar de a la identidad.
Esta es una de las estrategias en las que la IA realiza tareas que un ser humano prácticamente no puede llevar a cabo. Ningún planificador puede tener en la cabeza treinta mil registros de piezas y sus equivalentes entre distintos fabricantes. El agente sí puede.
10. Fiabilidad de los proveedores y gestión de los plazos de entrega
El flujo de trabajo. Se realiza un seguimiento del rendimiento de los proveedores y de los plazos de entrega reales, y esos datos se tienen en cuenta a la hora de calcular los pedidos de reposición y el stock de seguridad.
Donde se rompe. La fórmula de reposición se basa en el plazo de entrega que figura en el catálogo del proveedor o que se indica en la orden de compra original. Los plazos de entrega reales varían, a veces por motivos estacionales y otras por motivos estructurales. El cálculo se basa en una cifra que lleva dos años sin ser válida.
El problema fundamental es una lógica de reservas que resulta acertada sobre el papel, pero errónea en la práctica. O bien el stock de seguridad es demasiado reducido y te quedas sin existencias, o bien es demasiado elevado y acabas acumulando existencias que no necesitas. Ambas situaciones se deben a que se confía ciegamente en los plazos de entrega indicados en el catálogo.
Plazo de entrega estimado
El número que figura en el catálogo del proveedor. Se utiliza en la fórmula de reposición. Se actualiza con poca frecuencia. No refleja la volatilidad estacional, las interrupciones regionales ni el hecho de que un proveedor lleve seis meses retrasándose discretamente diez días.
Plazo de entrega real
Se calcula en tiempo real a partir del historial de pedidos. Se desglosa por proveedor, región y categoría de pieza. Se integra automáticamente en el cálculo de reabastecimiento para que el stock de seguridad se ajuste a la realidad, y no sea una cifra teórica.
La solución asistida por software. Las métricas en tiempo real sobre plazos de entrega y fiabilidad se extraen del historial de transacciones del ERP y se introducen en el motor de reposición. Los cálculos de las reservas se vuelven precisos. Esos mismos datos también aparecen en Estrategias de adquisición de MRO y los cuadros de mando de los proveedores, de modo que las decisiones de contratación dejen de basarse en las relaciones y empiecen a basarse en el rendimiento.
También conviene mencionar la disciplina funcional. La gestión de proveedores a través de la capa de MDM (véase gestión de datos maestros de proveedores) garantiza que el propio registro del proveedor esté limpio, sin duplicados y sea preciso antes de que se le asigne cualquier dato de rendimiento.
11. Centralización de existencias entre varias plantas y traspaso de existencias
El flujo de trabajo. La red de plantas se considera como un único almacén. Una pieza que está sin utilizar en una planta cubre una necesidad en otra, antes de que se emita un nuevo pedido de compra.
Donde se rompe. Cada planta gestiona sus propias existencias sin visibilidad entre centros. Una planta emite una solicitud de compra urgente para una pieza crítica que lleva nueve meses sin utilizarse en una planta asociada situada a ochenta kilómetros de distancia. El pedido se tramita, se duplica la pieza y el problema de exceso de existencias en la planta asociada se agrava.
El problema fundamental es que la red se comporta como un conjunto de compartimentos estancos, cuando debería funcionar como un todo integrado. Cada planta optimiza su funcionamiento a nivel local, pero es la red en su conjunto la que acaba pagando las consecuencias.
La solución asistida por software. Visibilidad del inventario en toda la red, con una estructura de identificación de piezas lo suficientemente clara (véase la estrategia 5) como para que el sistema sepa realmente que la misma pieza existe en dos centros bajo diferentes SKU. Cuando surge la necesidad, el sistema muestra la oportunidad de transferencia antes de que se genere la solicitud de compra. Esta es una de las medidas de mayor impacto disponibles en Gestión de inventarios MRO, y uno de los más sencillos en cuanto a su concepto una vez que se dispone de la base de datos maestros.
La escala de madurez que recorre los once
Si se analizan las once estrategias en su conjunto, se observa un patrón común. No fracasan porque sean estrategias erróneas, sino porque se están aplicando a un nivel de madurez que la empresa ya ha superado.
El paso de lo manual a lo sistematizado supone pasar de las personas a los sistemas. El trabajo que antes solo existía en la mente de alguien pasa ahora al CMMS, al ERP y al registro de activos. Se amplía a gran escala. Pero aún no piensa por sí mismo.
El paso de lo sistematizado a lo inteligente es el más interesante, y también el más difícil. Es el paso de la lógica estática a las decisiones en tiempo real. De reglas que eran válidas hace dos años a un razonamiento que se recalcula en función de los datos actuales. De talleres anuales a un ajuste continuo. De planificadores que realizan el arduo trabajo analítico a planificadores que realizan el trabajo de juicio que realmente requiere un ser humano.
Es en ese segundo paso donde el software diseñado desde el principio para la IA y los conocimientos técnicos dejan de ser temas independientes. Los agentes se encargan del trabajo que los humanos no pueden realizar a gran escala (puntuación, clasificación, análisis sintáctico y comparación entre millones de registros).
Los ingenieros de fiabilidad, los planificadores y los responsables de compras se encargan de las tareas que los agentes no pueden realizar (contexto, anulación de reglas y alineación con las prioridades empresariales). Cuando se mantiene ese equilibrio, las once estrategias dejan de ser once lagunas de madurez independientes y pasan a funcionar como un único sistema operativo coherente.
El punto de partida honesto
La mayoría de las empresas no necesitan avanzar en las once estrategias hasta alcanzar el nivel «Inteligente» de una sola vez. El punto de partida adecuado suele consistir en identificar las dos o tres estrategias que aún se encuentran en el nivel «Manual» o estancadas en el nivel «Sistematizado», corregir los datos maestros subyacentes y dejar que el resto avance de forma secuencial. El proceso de maduración es más importante que el nivel de maduración en sí.



