

Las métricas de fiabilidad como el MTTF se diseñaron para una era industrial más sencilla, cuando las cadenas de suministro eran estables, los activos estaban estandarizados y las consecuencias de los fallos se limitaban en gran medida a los costes de mantenimiento. Las operaciones actuales se enfrentan a un panorama de riesgos fundamentalmente distinto.
Lo que sobre el papel parece un problema menor de fiabilidad puede traducirse en un paro de la producción, una exposición a la normativa o una interrupción del suministro en la práctica. Por tanto, las decisiones de liderazgo requieren visibilidad del contexto operativo, no sólo promedios estadísticos.
Breve historia y necesidad del MTTF
Desde que existen los equipos industriales, los operarios se han planteado la misma pregunta fundamental: ¿cuándo fallará esto y tendré la pieza lista cuando lo haga?
Durante la mayor parte de la historia industrial, la respuesta era la experiencia, la intuición y el conocimiento tribal transmitido de un ingeniero de mantenimiento a otro.
A medida que los sistemas industriales se hicieron más complejos a mediados del siglo XX, ese planteamiento dejó de ser válido. Los ingenieros necesitaban una forma de cuantificar la fiabilidad, de convertir la pregunta "¿cuándo fallará esto?" en algo medible y comparable.
El tiempo medio hasta el fallo (MTTF) se convirtió en ese número. Proporcionaba una métrica simple y estándar: el tiempo medio que se espera que un componente funcione antes de fallar.
Para los componentes no reparables, se trata del MTTF; para los sistemas reparables, el equivalente es el tiempo medio entre fallos (MTBF). Ambos conceptos están estrechamente relacionados y a menudo se utilizan indistintamente, aunque técnicamente son distintos.
La elegancia de la métrica residía en su sencillez. Transformaba un concepto abstracto, la vida útil prevista de un componente físico, en una cifra utilizable sobre la que podían actuar los ingenieros de mantenimiento, los equipos de compras y los directores de operaciones.
El MTTF no sólo dio forma a los programas de mantenimiento. Influyó en el modo en que toda una generación de ingenieros concebía los activos como objetos con una vida útil predecible que podían gestionarse mediante el razonamiento estadístico.
La razón por la que el MTTF es tan importante como para examinarlo detenidamente es la magnitud de lo que está en juego cuando la planificación del mantenimiento es errónea.
Los fallos de los activos no son sólo un inconveniente técnico, sino que se traducen directamente en pérdidas de producción, costes de aprovisionamiento de emergencia y, en algunos casos, incidentes de seguridad y medioambientales.
Las cifras que figuran a continuación dan una idea del entorno operativo en el que se toman las decisiones basadas en el MTTF.
Ese marco persiste hoy en día. Entre en el departamento de planificación del mantenimiento de cualquier gran operador industrial, una refinería de petróleo, una empresa minera, una planta química, y encontrará que el MTTF y el MTBF siguen siendo el centro de la conversación.
Aparecen en estudios de mantenimiento centrados en la fiabilidad, en análisis modal de fallos y efectosen la configuración de SAP PM y en los programas de mantenimiento preventivo de Maximo.
Cómo se calcula el MTTF, con ejemplos prácticos
En esencia, el MTTF es el valor esperado de la distribución del tiempo de fallo de un componente. La definición formal es:
En la práctica, la mayoría de los equipos de mantenimiento no trabajan directamente con esta integral. Utilizan la versión simplificada que surge cuando se supone una tasa de fallos constante, que es la distribución exponencial:
Este supuesto de velocidad constante es lo que hace que el MTTF sea fácil de calcular y utilizar.
Ejemplo práctico: Tres componentes de una bomba centrífuga
Consideremos una bomba centrífuga en el circuito de agua de refrigeración de una refinería. Un ingeniero de fiabilidad quiere calcular el MTTF de tres componentes clave y utilizar esas cifras para establecer los intervalos de mantenimiento preventivo y los niveles de existencias de seguridad. Así es como funciona el cálculo en la práctica:
| Componente | Fallos observados | Horas totales de funcionamiento | Tasa de fallos (λ) | MTTF | Intervalo PM sugerido |
|---|---|---|---|---|---|
| Cierre mecánico | 6 fallos | 12.000 horas | 0,0005 /hr | 2.000 horas (~12 meses) | Sustituir a las 1.600 horas |
| Cojinete (radial) | 3 fallos | 18.000 horas | 0,000167 /hr | 6.000 horas (~36 meses) | Inspeccionar a las 4.500 horas |
| Rodete | 1 fallo | 15.000 horas | 0,0000667 /hr | 15.000 horas (~7 años) | Inspeccionar en la revisión general |
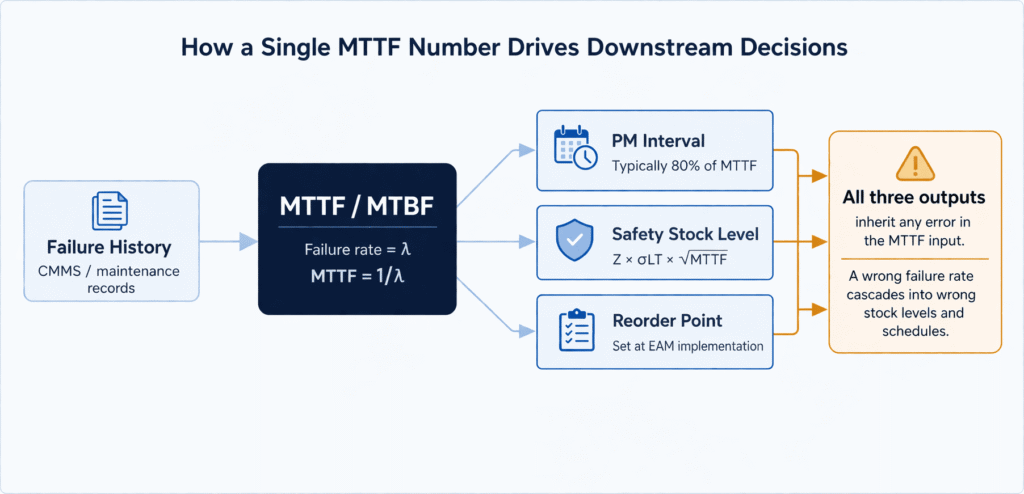
El MTTF de 2.000 horas de la junta mecánica indica al almacén que debe tener al menos una junta de repuesto en stock en todo momento. El MTTF de 6.000 horas del rodamiento sugiere una prioridad de almacenamiento menor.
El MTTF de 15.000 horas del impulsor lo convierte en una pieza bajo demanda para la mayoría de las operaciones. MTTF hace exactamente aquello para lo que fue diseñado, y lo hace bien.
El sencillo cálculo anterior supone que los fallos se producen a un ritmo constante durante toda la vida útil del componente. En realidad, la mayoría de los componentes siguen un patrón conocido como la curva de la bañera: tasas de fallo más altas cuando son nuevos (mortalidad infantil por errores de instalación), un periodo medio estable y tasas de fallo crecientes a medida que el componente envejece y se desgasta.
La distribución de Weibull refleja esta realidad. Su parámetro de forma β indica en qué parte de la curva se encuentra un componente:
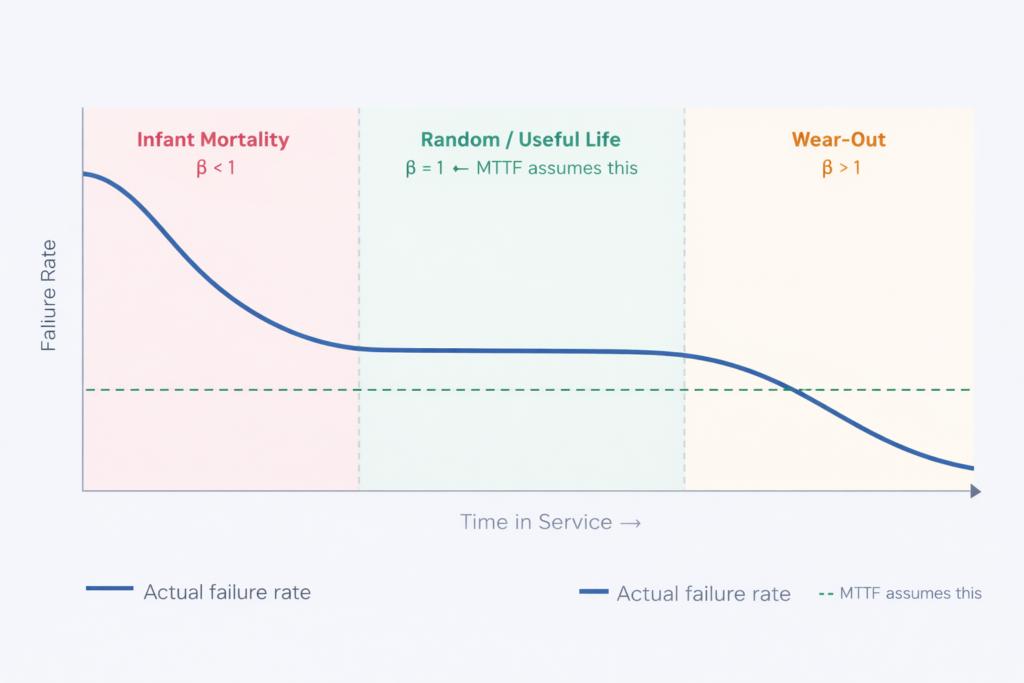
La mayoría de las plataformas EAM asumen una tasa de fallos constante (β = 1, línea verde discontinua). Los activos industriales reales en fase de desgaste tienen β > 1, lo que significa que la MTTF subestima sistemáticamente el riesgo a medida que los equipos envejecen. (Fuente: Revista Reliability)
| Valor β | Fase del ciclo de vida | Qué significa para la junta de la bomba Ejemplo |
|---|---|---|
| β < 1 | Mortalidad infantil | La junta falla poco después de la instalación. Causa probable: montaje incorrecto, grado especificado incorrecto. El cálculo MTTF estándar basado en estos datos subestimará la vida operativa normal. |
| β = 1 | Aleatorio / Vida útil | Los fallos se producen a un ritmo constante e impredecible. El MTTF es una herramienta de planificación válida en este caso. Es la única fase en la que la hipótesis estándar MTTF es matemáticamente correcta. |
| β > 1 | Desgaste | La junta está envejeciendo y la tasa de fallos está aumentando. Un intervalo PM fijado en 80% de MTTF basado en datos de vida útil temprana será ahora demasiado largo, y se producirán fallos antes de la sustitución programada. |
La mayoría de las plataformas EAM utilizan por defecto distribuciones exponenciales (β = 1). En el caso de los activos industriales envejecidos, β > 1 es habitual, por lo que el MTTF estático no es fiable.
A Estudio de la NASA de 30 cojinetes idénticos rodados hasta el fallo en condiciones controladascitado en Reliability Magazine, descubrieron una variación tan elevada que los calendarios de cambio basados en el MTTF estándar resultaban estadísticamente indefendibles.
La relación entre el MTTF y la planificación de inventarios es directa. La mayoría de los sistemas ERP calculan las existencias de seguridad mediante una fórmula derivada de la tasa de fallos:
Para la junta de la bomba de nuestro ejemplo: si el MTTF es de 2.000 horas, el nivel de servicio objetivo es 95% (Z = 1,65), y el plazo de entrega de la junta por parte de su proveedor tiene una desviación estándar de 2 semanas, el cálculo de las existencias de seguridad producirá una recomendación específica de unidades a retener.
Y lo que es más importante, si la MTTF es errónea porque se ha calculado a partir de una población heterogénea o en condiciones de funcionamiento diferentes, todas las decisiones de inventario posteriores serán erróneas por el mismo margen.
El papel del MTTF en el mantenimiento y el inventario MRO
Antes de explorar las limitaciones, conviene ser directo sobre lo que MTTF acierta, porque la tentación en el discurso tecnológico es descartar lo viejo en favor de lo nuevo. En este caso sería un error.
Los seres humanos somos malos jueces de la probabilidad de fallo a lo largo del tiempo. Sobrevaloramos la fiabilidad de los equipos que hemos revisado recientemente y subestimamos la degradación de los que han estado funcionando en silencio.
El MTTF obliga a las organizaciones a sustituir la intuición por el cálculo. A una bomba con un MTTF de 18 meses no le importa si el ingeniero de mantenimiento cree que está bien. La estadística no es una opinión.
Los ingenieros de mantenimiento, los equipos de compras, los directores de operaciones y los directores financieros necesitan hablar del riesgo de los activos. MTTF les proporciona un vocabulario común.
Su normalización en ISO 14224, MIL-HDBK-217, e IEC 60812 significa que un ingeniero de fiabilidad que se traslade de un sector a otro no necesita aprender un nuevo marco.
Sin una estimación de la vida útil prevista, la programación del mantenimiento preventivo puede ser excesivamente conservadora, sustituyendo piezas con una vida útil restante significativa, o poco conservadora, esperando a que fallen los componentes.
El MTTF proporciona el anclaje racional. Un rodamiento radial con un MTTF de 6.000 horas debe inspeccionarse a las 4.500 horas, no a las 3.000 (despilfarro) ni a las 8.000 (riesgo).
La junta de bomba que falla cada 2.000 horas en un parque de diez bombas genera una demanda anual previsible de juntas. Esa estimación de la demanda, por imperfecta que sea, es la base de la lógica de reposición del almacén.
Cada evaluación de la criticidad de las piezas de recambio se asienta en última instancia sobre alguna versión de esta traducción de la tasa de fallos a la demanda.
La MTTF no es errónea. Es incompleto. La distinción es muy importante a la hora de decidir qué construir.
A quién pertenece el MTTF en las operaciones industriales
A diferencia del FMEA, que tiene una estructura de propiedad claramente definida entre las distintas funciones, el MTTF tiende a pertenecer por fragmentos a toda la organización.
Entender dónde vive, y dónde no, ayuda a explicar por qué a menudo no se abordan sus limitaciones.
Ingeniería de fiabilidad
Calcula el MTTF a partir de los datos del historial de fallos de la GMAO, establece los intervalos PM, y suele ser la única función que comprende las hipótesis las suposiciones estadísticas en las que se basa la cifra. A menudo es el único custodio de si la hipótesis β de Weibull es válida para un activo determinado.
Planificación del mantenimiento y adquisición de MRR
Utiliza las estimaciones de demanda derivadas del MTTF para establecer puntos de pedido y niveles de stock de seguridad en el ERP. de seguridad en el ERP. Rara vez cuestiona la calidad de la información MTTF, y tiene visibilidad limitada sobre si la tasa de fallos utilizada sigue siendo válida para las condiciones operativas actuales.
Operaciones / Gestión de plantas
La consecuencia de un MTTF erróneo es un tiempo de inactividad no planificado o un coste de mantenimiento excesivo. o costes de mantenimiento excesivos. Proporciona el contexto de producción (cómo de crítico es este activo hoy en día, a qué está funcionando realmente) que los cálculos MTTF rara vez incorporan.
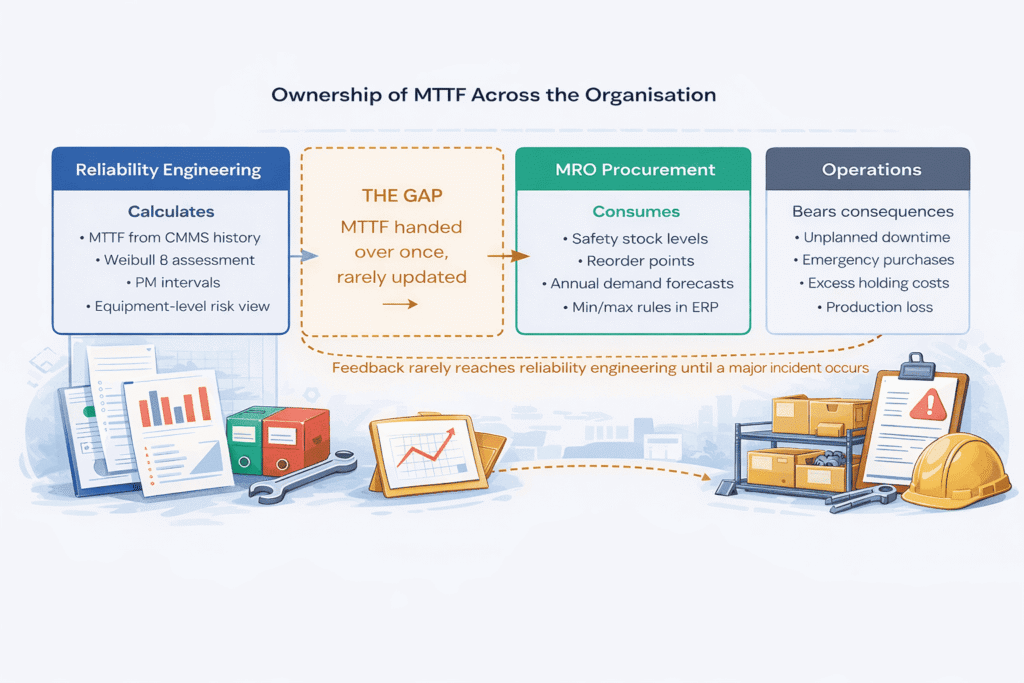
En la mayoría de las organizaciones industriales, la persona que calcula el MTTF (ingeniería de fiabilidad) y la persona que lo utiliza para tomar decisiones decisiones de inventario (aprovisionamiento MRO) trabajan en sistemas separados, con KPIs separados y con una interacción limitada. La estimación de la tasa de fallos se una vez, en la implantación de EAM o durante una revisión anual, y luego se utiliza hasta que algo se rompe lo suficientemente hasta que se produce una avería lo suficientemente grave como para volver a calcularla. En separación es donde se origina una proporción significativa del exceso de inventario y del riesgo de ruptura de existencias. el riesgo de ruptura de existencias.
Dónde se rompe estructuralmente el MTTF
En conversaciones con clientes que utilizan ampliamente el MTTF como principal insumo de planificación, afloran sistemáticamente las mismas limitaciones. No se trata de críticas teóricas. Son fallos operativos que aparecen en los informes de pérdidas de producción.
La validez estadística del MTTF se basa en una población de componentes idénticos que funcionan en condiciones idénticas. Este supuesto es válido en un laboratorio controlado. Rara vez se cumple en un emplazamiento industrial.
En el caso de dos bombas centrífugas nominalmente idénticas en la misma instalación, la bomba A funciona a 80% de capacidad nominal con agua limpia a 20°C. La bomba B funciona a 110% de capacidad nominal con fluido ligeramente corrosivo a 35°C.
Sus cierres mecánicos tienen el mismo número de pieza del fabricante. Sus distribuciones de fallos reales son significativamente diferentes.
Un único MTTF calculado a partir de la población combinada de ambas bombas no dice nada fiable sobre ninguna de ellas en concreto.
Investigación publicada en Reliability Magazine señala este punto con precisión: a medida que las organizaciones mejoran sus prácticas de fiabilidad y comienzan a analizar los datos de fallos a nivel de activo específico en lugar de a nivel de clase de componente, la varianza en torno a los valores MTTF de la población suele aumentar en lugar de disminuir, porque se hacen visibles modos de fallo más profundos y específicos de los activos que antes se promediaban.
Precisamente por eso creación de un programa de criticidad a nivel de activo individualen lugar del nivel de clase de componente, produce resultados significativamente diferentes.
Caso práctico de un cliente
Una importante refinería de la costa del Golfo descubrió que su programa de mantenimiento preventivo basado en el MTTF realizaba simultáneamente un mantenimiento excesivo de 40% de sus bombas (sustituyendo componentes con una vida útil restante significativa) y un mantenimiento insuficiente de 23% (omitiendo componentes que se degradaban más rápidamente que la media de la población). El coste del mantenimiento excesivo se ocultó en mano de obra y materiales innecesarios. El coste del mantenimiento insuficiente aparecía en el informe de pérdidas de producción. Ninguno de los dos aparecía en el cálculo del MTTF.
El MTTF se calcula a partir de datos históricos bajo un conjunto específico de condiciones de funcionamiento. En el momento en que esas condiciones cambian, la cifra calculada empieza a alejarse de la realidad.
En la bibliografía sobre ingeniería de la fiabilidad aparecen sistemáticamente varias variables como las más importantes:
| Variable | Efecto práctico en la tasa de fallos | Qué hace MTTF con esto |
|---|---|---|
| Carga de funcionamiento superior a la capacidad nominal | Los componentes se desgastan más rápido; las juntas y los cojinetes son especialmente sensibles a la sobrepresión y al calor. | No modelizado. El MTTF calculado con carga nominal no varía. |
| Temperatura ambiente y del proceso | Según el principio de Arrhenius, la vida útil de los rodamientos y del aislamiento se reduce a la mitad cada 10 °C por encima de la temperatura nominal. | No se ha modelizado. La temperatura no es una variable en los cálculos MTTF estándar. |
| Cambio en la composición del fluido de proceso | Una junta apta para fluidos de pH neutro se degrada mucho más rápido en servicios ácidos o de alta viscosidad. | No se ha modelizado. Se sigue utilizando el MTTF de los datos del servicio neutral. |
| Calidad de instalación y mantenimiento | Los fallos de mortalidad infantil posteriores al mantenimiento son frecuentes cuando las juntas o los rodamientos se reinstalan de forma incorrecta. | Estos fallos tempranos sesgan a la baja el MTTF de la población sin explicar por qué. |
| Humedad y entorno corrosivo | Degradación acelerada de la superficie de las juntas mecánicas y los contactos eléctricos en entornos costeros o húmedos. | No se modeliza a menos que se separen los datos de fallos específicos del lugar de la población global. |
El MTTF se calcula a partir de datos históricos de fallos. Describe lo que le ha ocurrido a una población de componentes en el pasado. Pero un planificador de mantenimiento toma decisiones sobre el futuro: qué fallará, cuándo y qué hay que tener en stock cuando ocurra.
Un rodamiento que actualmente vibra al doble de su frecuencia base no está comunicando esa información a un cálculo MTTF.
Un transformador que funciona cinco grados más caliente de lo normal debido a un problema de instalación hace seis meses no se refleja en una estadística a nivel de población. Cuando el nuevo fallo entra en el conjunto de datos y actualiza el MTTF, el daño ya está hecho.
El MTTF indica cuándo es probable que falle un componente. No dice nada sobre si la pieza de repuesto estará disponible cuando lo haga.
Esta es la laguna más importante, y la que apenas recibe atención en la literatura clásica sobre ingeniería de la fiabilidad.
La junta de una bomba de refinería tiene un MTTF de 2.000 horas. El ingeniero de fiabilidad establece un intervalo PM de 1.600 horas. El equipo de compras establece un punto de pedido basado en esa tasa de fallos. Lo que el modelo no sabe es que el único proveedor proveedor cualificado tiene un plazo de entrega de 14 semanas debido a limitaciones de fabricación. El almacén se queda sin existencias. La junta falla a las 1.700 horas. El plazo de entrega significa que la bomba bomba funciona durante 6 semanas con una junta defectuosa antes de que llegue un repuesto. El MTTF era correcto. El sistema falló de todos modos.
Cuando las estimaciones de demanda derivadas del MTTF se entregan a los equipos de compras, se enfrentan a un problema estadístico que el MTTF nunca fue diseñado para resolver.
Una junta de bomba crítica que se consume una vez cada 14 meses no genera una señal de demanda suave. Genera una serie de ceros puntuados por unos ocasionales.
Un impulsor que permanece intacto durante tres años y luego se necesita dos veces en seis semanas no es una anomalía de programación. Es un patrón normal para piezas de repuesto de bajo volumen y alta criticidad.
Los métodos estándar de previsión, medias móviles, suavización exponencial, aplicados a estos patrones intermitentes producen sistemáticamente una respuesta errónea.
Pronostican en exceso los artículos con picos de demanda ocasionales e infravaloran los artículos con un consumo poco frecuente pero agrupado.
La literatura académica al respecto está bien establecida: Método de Croston (1972)desarrollado específicamente para la demanda intermitente, demostró que el suavizado exponencial estándar es estadísticamente inadecuado para estos patrones, y sus variantes se han validado en datos de inventario de la RAF que abarcan más de 11.000 series de piezas de recambio.
Un activo que funciona con un equipo de 20 años de antigüedad no se enfrenta simplemente a los riesgos de fallo que capta el MTTF. Se enfrenta a un riesgo creciente que el MTTF no tiene ningún mecanismo para representar: es posible que las piezas necesarias para repararlo ya no se fabriquen.
MTTF calculará correctamente que un actuador de válvula crítico tiene una vida útil media de 36 meses hasta el día en que el OEM deje de fabricar el componente.
En ese momento, es posible que al almacén le queden tres meses de existencias, que no se haya identificado ninguna alternativa cualificada y que el plazo para encontrar un sustituto sea de 12 meses. El riesgo de fallo no cambió. El riesgo de suministro hacía que el activo fuera inmanejable.
En los sectores con gran cantidad de activos, en los que la vida útil de los equipos supera habitualmente los 30 o 40 años, la obsolescencia no es un caso aislado. Es una exposición sistemática y creciente que las métricas de fiabilidad estáticas son estructuralmente incapaces de representar.
Un análisis MTTF estándar no distingue entre el fallo de una junta $12 que provoca un retraso de 30 minutos y el fallo de una válvula de control $4.000 que deja fuera de servicio una unidad de producción durante seis días. Ambos son fallos. Ambos contribuyen a la estadística MTTF.
Pero las consecuencias no son ni remotamente comparables, y una estrategia de mantenimiento que las considere equivalentes está asignando sistemáticamente mal los recursos, invirtiendo en exceso en la prevención de fallos de baja consecuencia e invirtiendo poco en la prevención de los de alta consecuencia.
El coste de confiar en una tasa de fallos estática
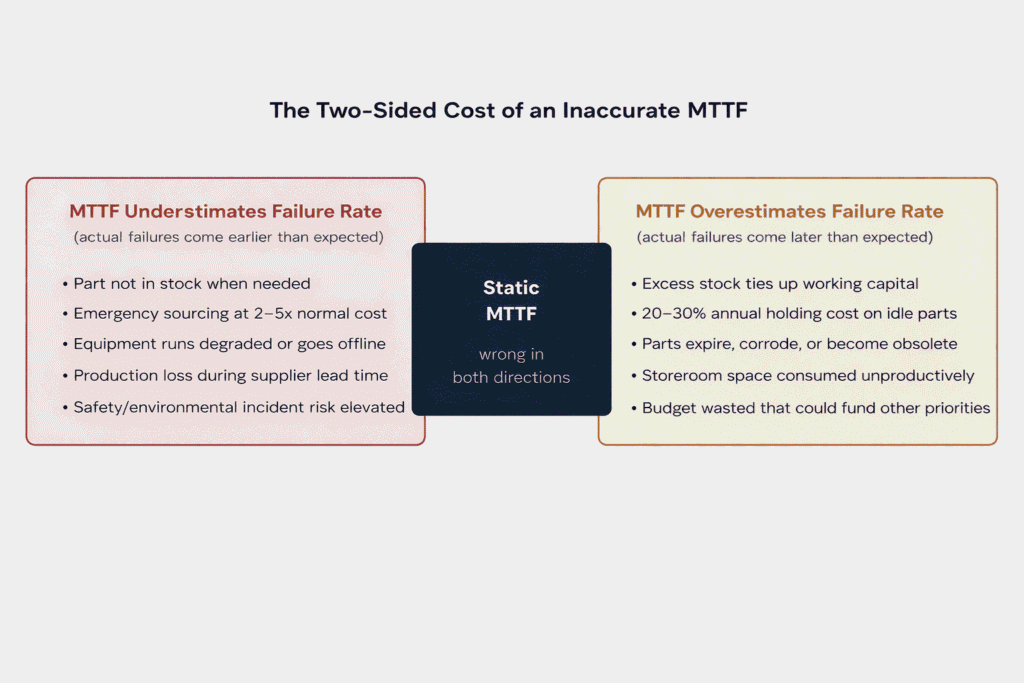
En la gestión de inventarios MRO, un MTTF inexacto crea el mismo problema de dos caras que las puntuaciones de criticidad FMEA defectuosas: exceso de existencias y falta de existencias simultáneas, cada una costosa de diferentes maneras.
Un activo cuya tasa de fallos real sea superior a la que sugiere el MTTF, porque las condiciones de funcionamiento hayan cambiado, porque el componente esté en fase de desgaste o porque la media de la población oculte la tensión específica del emplazamiento, fallará antes de la sustitución prevista.
Si la pieza no está en stock y el plazo de entrega del proveedor es de semanas en lugar de días, el resultado es un tiempo de inactividad imprevisto.
En operaciones de petróleo y gas, Encuesta de ABB sobre el valor de la fiabilidad en 2025 de 3.600 responsables de la toma de decisiones en todo el mundo descubrió que, según 83%, las paradas imprevistas cuestan al menos $10.000 por hora, con costes que alcanzan $500.000 por hora en las unidades de proceso más importantes.
Un activo que falla con menos frecuencia de lo que sugiere la media de la población, porque funciona con poca carga, en un entorno benigno o con una excelente calidad de mantenimiento, tendrá piezas en el almacén consumiendo capital.
Cada pieza de recambio almacenada conlleva un coste de mantenimiento anual estimado entre 20 y 30% de su valor, que cubre el coste de capital de las existencias, los gastos generales de gestión del almacén y los gastos relacionados con la logística.
La consecuencia práctica es una organización de mantenimiento que lucha perpetuamente en dos frentes de piezas críticas a precios de emergencia y, al mismo tiempo, gestionar un almacén al tiempo que gestiona un almacén abarrotado de piezas que nunca se moverán. Ambos problemas se remontan a la misma causa: una tasa de fallos calculada calculado a partir de datos históricos, en condiciones históricas y sin realidad cambia.
La propia investigación de Verdantis con casi 1.900 altos ejecutivos de los sectores de minería, petróleo y energía, servicios públicos y fabricación reveló que 51% citó los problemas de calidad de los datos en las operaciones de MRR como principal retoy 49% notificaron incoherencias en los datos maestros de los proveedores.
No se trata de lagunas tecnológicas. Son los fallos en la disciplina de los datos que hacen que cualquier modelo, basado en el MTTF o de otro tipo, no sea fiable en el punto de decisión.
Más allá del MTTF: cómo la gestión moderna de activos evoluciona el enfoque
El MTTF no necesita ser sustituido. Hay que entenderlo como lo que es: un punto de partida, no un punto final.
La cuestión es qué contexto adicional, datos y capacidad analítica pueden superponerse para producir decisiones más precisas, más actuales y más completas.
La dirección que está tomando la gestión moderna de activos empresariales es la de tratar la probabilidad de fallo como una variable entre muchas otras, en lugar de como la variable principal que impulsa todas las decisiones posteriores.
Un modelo de criticidad significativo para una pieza de recambio no sólo pregunta "¿cuándo falla este componente por término medio?", sino también: ¿cuál es la consecuencia para la producción si falla hoy? ¿Cuál es el plazo de entrega actual del proveedor? ¿Existe un sustituto cualificado? ¿Ha indicado el fabricante algún riesgo de fin de vida útil de este componente? ¿Hay alguna planta hermana que tenga existencias?
La planificación sólo MTTF pregunta
La criticidad multivariable pregunta
Esta es la evolución práctica que herramientas como el Módulo de criticidad MRO 360 se construyen alrededor.
En lugar de reemplazar la probabilidad de fallo derivada del MTTF, la incorporan como una entrada en un modelo más amplio que también tiene en cuenta el historial de plazos de entrega del proveedor, la visibilidad de las existencias entre plantas, el contexto de la programación de la producción, la sustituibilidad de las piezas y el estado de obsolescencia.
La base del MTTF se mantiene. Lo que cambia es lo que alimenta y la frecuencia con que se actualizan todas las entradas.
| Dimensión | Planificación basada en el MTTF | Criticidad multivariable |
|---|---|---|
| Frecuencia de actualización | Establecido en el momento de la implantación de EAM; se actualiza con poca frecuencia. | Continuo, reevaluado cuando cambian las condiciones de funcionamiento |
| Alcance | Media de la población para una clase de componente | Específicos para cada activo, que incorporan el contexto operativo individual |
| Variables | Sólo tiempo hasta fallo | Probabilidad de fallo, plazo de entrega del proveedor, criticidad, sustituibilidad, estado de obsolescencia |
| Previsión de la demanda | Alisamiento exponencial estándar; estadísticamente inadecuado para la demanda intermitente de MRR. | Métodos específicos de demanda intermitente (Croston y variantes) validados con datos de piezas de recambio. |
| Riesgo para los proveedores | No en el modelo | Integrado: historial de plazos de entrega y fiabilidad de entrega por combinación pieza-proveedor |
| Obsolescencia | No hay mecanismo; los eventos EOL son invisibles hasta que provocan una ruptura de existencias | Supervisión: seguimiento del estado del ciclo de vida del fabricante; identificación proactiva de sustitutos. |
| Salida | Intervalo PM en horas o meses | Cola de trabajo clasificada por riesgos con impacto financiero y estado de la cadena de suministro |
Metodologías relacionadas
Las organizaciones con programas de fiabilidad maduros rara vez utilizan el MTTF de forma aislada. Forma parte de un ecosistema más amplio de marcos analíticos, cada uno de los cuales aborda el problema del fallo de los activos desde un ángulo diferente.
| Marco | Acérquese a | Relación con el MTTF |
|---|---|---|
| AMFE / FMECA | Identificación sistemática de los modos de fallo, sus efectos y las puntuaciones de prioridad de los riesgos en todos los componentes. | El MTTF alimenta la puntuación de Ocurrencia (O) en el AMFE. El AMFE proporciona el contexto del modo de fallo que hace que el MTTF sea más interpretable. |
| Mantenimiento centrado en la fiabilidad (RCM) | Enfoque holístico para determinar qué tareas de mantenimiento son necesarias, basado en el análisis de fallos funcionales. | La RCM utiliza el MTTF para establecer los intervalos entre tareas. También se pregunta si el mantenimiento basado en el tiempo (MTTF) es la estrategia adecuada para un determinado modo de fallo. |
| Análisis del árbol de fallos (FTA) | Método deductivo descendente que parte de un fallo conocido y rastrea sus causas profundas. | Mientras que el MTTF pregunta "¿con qué frecuencia falla esto?", el FTA pregunta "¿por qué se ha producido este fallo concreto?". Son complementarios: El MTTF cuantifica la frecuencia, el FTA explica la causa. |
| Inspección basada en el riesgo (RBI) | Prioriza las actividades de inspección en función de las consecuencias y la probabilidad de fallo de los equipos. | RBI utiliza la probabilidad de fallo (relacionada con el MTTF) junto con la consecuencia de fallo. Se aplica principalmente a equipos estáticos: recipientes a presión, tuberías, depósitos. |
| Fiabilidad, disponibilidad y mantenibilidad (RAM) | Análisis cuantitativo que modela la frecuencia con la que fallan los equipos, la rapidez con la que se restablecen y su disponibilidad para la producción. | El MTTF es una entrada directa al análisis RAM. La RAM traduce las tasas de fallo a nivel de componente en predicciones de disponibilidad a nivel de sistema. |



