

What if you could run a critical asset to failure without shutting down production, test a maintenance decision before implementing it, or have advance notice of the remaining useful life of a pump by months?
But most teams don’t have that capability. They use time-based, periodic inspections and condition monitoring. For such teams, failures continue to pop up out of the blue, because failure signals are interpreted too late. It is in that lag between what the system is telling and when the maintenance team makes a decision that risk accumulates quietly over time.
A digital twin bridges that lag by producing a live, data-driven model that enables teams to predict, test, and take action before failure happens. Let’s explore how a digital twin can be used for predictive maintenance.
What is a Digital Twin?
A digital twin is an active virtual representation of a physical asset that is continuously updated with the asset’s real-world behavior. It is based on live data coming from sensors and connected systems. The digital model can be updated instantly with changes in performance, a change in condition, or a change in the operating environment. This constant updating enables the model to be used for the entire life cycle of the asset and not just for a single, or delayed, snapshot in time.
A digital twin is not a 3D visualization, nor is it a static simulation that relies on assumptions. It’s a system that simulates behavior in real-world environments, and self-updates as those environment conditions change in real-time.
When that connection to real-time data becomes compromised, digitized models no longer represent reality, which directly impacts the reliability of decisions. In practical terms, a twin without data continuity is not a genuine digital twin.
This linkage between the physical asset and its digital twin enables a system where data is not simply observed but contextualized. Teams can use the model to run tests, analyze results, and make better-informed decisions before changing field protocols as new signals come in.
Digital Twin vs Condition Monitoring
Digital twin and condition monitoring use asset data, but they differ in the way that data affects decisions. The difference is not in access to data, but in whether you can move from monitoring to predicting.
Monitoring Systems: Visibility Without Foresight
Condition monitoring systems concentrate on the recognition of abnormality. They pull sensor data periodically and push alerts after set thresholds are breached, which enables teams to spot problems at their nascent stages. This strategy increases visibility, but also relies on responding after a change is visible, which limits the extent to which intervention can be undertaken early.
Digital Twins: Simulation-Driven Decision Support
A digital twin goes further than detection by consistently analyzing how an asset performs in the real world. Rather than waiting for thresholds, it predicts how the asset will perform under various conditions, enabling teams to assess courses of action prior to taking them. This capability to test decisions virtually reduces uncertainty and enables a shift in maintenance from reactive to predictive.
Here’s a quick overview of the differences between condition monitoring systems and a digital twin.
| Factor | Control de las condiciones | Gemelo digital |
|---|---|---|
| Core purpose | Detects deviations from expected operating limits | Simulates behavior to evaluate and predict outcomes |
| Data usage | Uses periodic or threshold-based sensor readings | Combines continuous real-time data with behavioral models |
| Time focus | Focused on current condition and recent changes | Extends from present behavior into future scenarios |
| Insight level | Generates alerts based on predefined limits | Interprets patterns, causes, and potential outcomes |
| Decision type | Decisions follow detected issues | Decisions are validated before issues occur |
| Action timing | Intervention begins after deviation appears | Intervention is planned ahead of potential failure |
| Capability | Identifies anomalies in operation | Tests actions and scenarios in a virtual environment |
Why Digital Twin Matters in Maintenance
Though traditional systems retrieve signals and surface the latest conditions, it is generally where visibility stops. It’s followed by manual interpretation and action. This causes a delay between the moment the asset is sending signals and when a decision is actually taken, and it is that delay that causes the failures to form.
In reality, maintenance crews are often stuck in a loop of capturing, assessing, and then responding to data once a deviation is apparent. This stage creates a period between signal, interpretation, and decision, thus the action is delayed. As a result, maintenance is reactive, and actions are taken only after failures have happened.
A digital twin changes this by connecting data straight to predictive insight, so the system is not only telling you what is happening, but also what it is expecting to happen next. By integrating live signals with patterns from the past and model-driven behavior, it supports earlier actions and reduces dependence on lagged human analysis.
Companies that adopt this approach of predictive maintenance claim up to 50% reduction in unplanned downtime and considerable improvements in productivity with fewer unexpected breakdowns. This is a move from maintenance responding to what is visible to maintenance acting on emerging conditions, which is even more pronounced in the manufacturing industry, where asset performance has a direct impact on production continuity.
Digital Twin in Manufacturing: Where it Delivers the Most Value
A digital twin for manufacturing reproduces machines in real time and shows how they react to changing loads, environmental conditions, and usage patterns. There is no need to wait for thresholds to trigger alarms. The system performs a continuous behavior analysis of the signals and provides teams with the ability to detect early indications of wear, inefficiency, and imbalance that could lead to failures resulting in lost production. The effect is more pronounced when dealing with high-value assets such as turbines, pumps, and CNC machines, where unanticipated downtime is extremely expensive.
A digital twin is used to support operations and maintenance by bridging production performance with asset condition, so that decisions are not made in a silo. Maintenance crews can schedule interventions with greater precision, and operations teams can see how the behavior of equipment shapes their output.
At this point, the digital twin is a decision support system rather than a monitoring system.
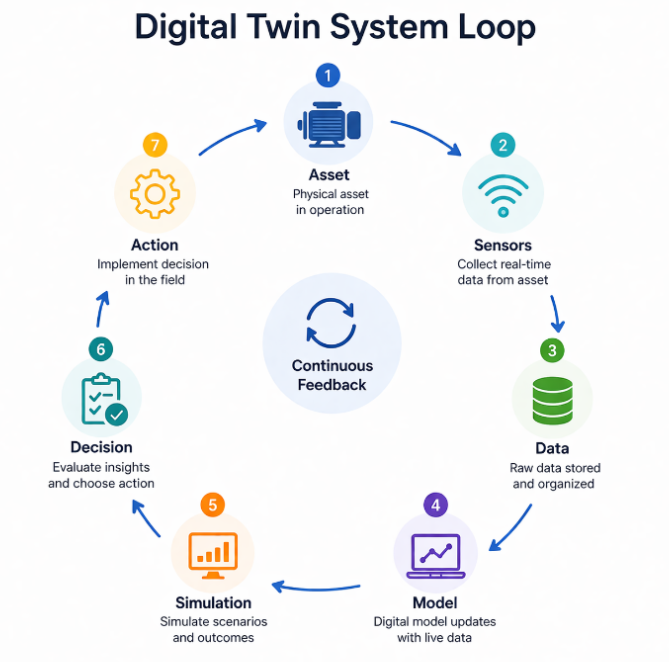
How a Digital Twin Works
Imagine a pump running on and off with temperature, vibration, and pressure starting to change gradually. These signals are continuously recorded and are processed using a digital model not only of the current state but also of the future evolution of the asset under those conditions.
As this data arrives, the model does not wait for a threshold to be exceeded. It is updated in near real time, integrating new data with historical patterns and the operating context to help make sense of those changes. Using a digital twin, teams can detect variations that cannot be spotted visibly, where such changes signify the early-stage of deterioration or imbalance. They can then test numerous scenarios across different failure states, testing how the asset might behave under various loads, stresses, or faults.
Instead of responding to one outcome, the monitoring system considers multiple futures and even assists in validating which choice minimizes risks the most. Since these simulations are conducted in a virtual environment, teams can try out their decisions without risking physical asset failure or downtime.
In more advanced implementations, this flow becomes bidirectional, where decisions taken in the field feed back into the model, improving its accuracy over time. The system continues to learn from each cycle of operation, simulation, and action, which gradually reduces the gap between signal and decision.
Digital Twin Infrastructure Features
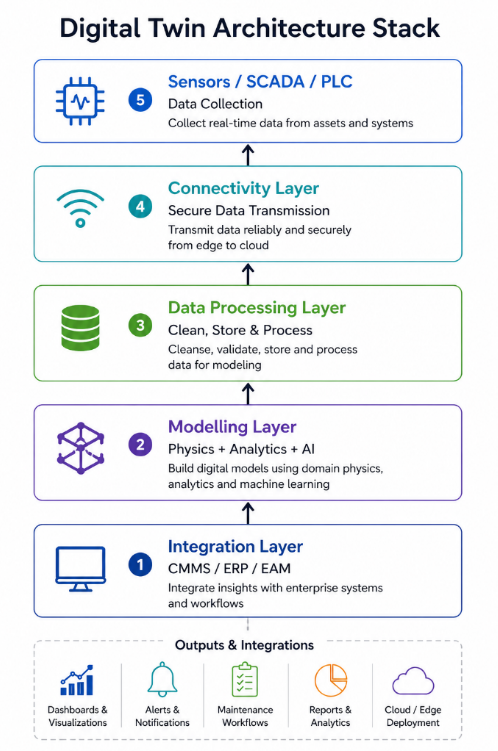
A digital twin relies on uninterrupted cooperation among various systems, as each layer influences how closely the model represents the physical asset. If data collection goes wrong at the source, the model doesn’t have anything reliable to read, and if integration goes wrong at the end, even powerful insights can’t be turned into action. The digital twin infrastructure includes the following core components:
Data Capture
Everything starts with the asset itself. As the asset runs through variable loads and conditions, sensors and industrial systems like SCADA and PLCs capture signals. When this layer is missing, it’s not just that the system can’t see, it’s that it can no longer meaningfully represent behavior.
Data Flow and Processing
Collected data travels over networks and gateways and arrives in processing environments where it is cleaned and organized. This phase is often overlooked, but this is the point when raw signals get transformed into inputs or are considered too noisy to use. Data pipelines need to support real-time streams without latency or loss, which is challenging in environments with legacy systems and siloed architectures.
Modeling
Once the data has been organized, the model attempts to show what the asset does in the real world. Its reliability depends not only on the model alone but on the data consistency and quality over time. Minor errors early on can often show up as incorrect simulations or misleading predictions at this stage.
Integración
The final layer connects the model to maintenance and operational systems such as CMMS and ERP platforms. Without this connection, insights remain theoretical, and decisions stall before execution. This is where many implementations fail, not due to lack of insight, but due to lack of system alignment.
Here are the crucial layers in a digital twin infrastructure:
| Capa | What it Includes | Role in the System | Failure Risk if Weak |
|---|---|---|---|
| Capa física | Sensors, IoT devices, SCADA, PLC systems | Capture real-time signals from asset behavior | Incomplete, delayed, or noisy data |
| Connectivity | Networks, gateways, data transfer protocols | Move data continuously between systems | Latency, interruptions, or data loss |
| Data processing | Cloud platforms, edge computing, data pipelines | Clean, structure, and prepare data for modelling | Inconsistent or unusable insights |
| Modelling layer | Simulation engines and behavioral models | Replicate asset behavior under real conditions | Incorrect predictions and poor simulation accuracy |
| Integration layer | CMMS, ERP, maintenance systems | Translate insights into executable actions | Decisions remain unimplemented |
Each layer depends on the one before it, which means the system is only as strong as its weakest link. In many cases, issues such as inconsistent asset naming, missing hierarchy relationships, or duplicate records introduce noise that reduces model reliability before simulation even begins. Once this foundation holds, the conversation shifts from building the system to understanding the level of capability that the system can actually deliver.
Maturity Levels of Digital Twin Capabilities
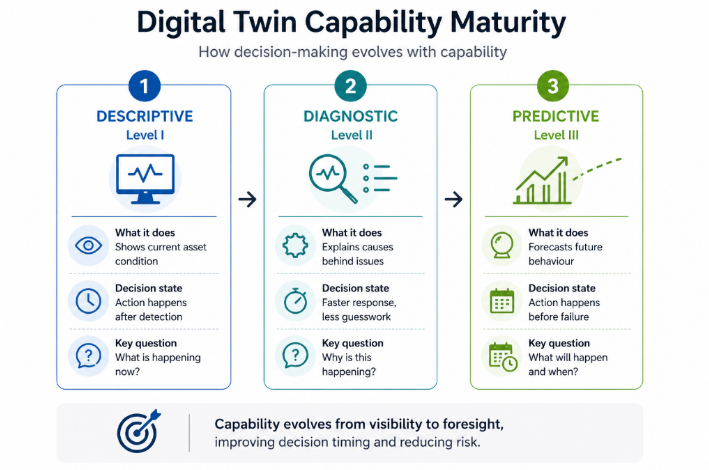
Once the infrastructure is strong, the attention turns from building the system to what it can actually do. Digital twin functionality is expected to evolve over time; each phase will transform how decisions are made rather than how data is visually represented.
Descriptive Capability: Level I
A descriptive twin enables persistent visibility into asset condition in the early stage, enhancing awareness, but it does not transform the timing of decision-making. Teams have the ability to monitor performance live. But the action can only follow detection even though the monitoring signals are continuous and steady.
Diagnostic Capability: Level II
As a system develops, it starts to link signals to root causes, which means it shortens the post-facto inquiry for some problems. Teams can approach resolution more directly and with more certainty, rather than trying to make sense of multiple options. Although they both become more reactive, the speed of decisions gets better at this stage.
Predictive Control: Level III
The biggest and most significant change of state occurs when the system begins to predict future states based on current conditions and past history patterns. Decisions are made in advance of failure, enabling teams to schedule interventions prior to impact on performance. This level needs repeatable data, steady models, and a tightly coupled system. Teams can reach this capability gradually, starting from continuous, live monitoring.
Here are the crucial layers in a digital twin infrastructure:
| Capability Level | What it Shows | Key Question Answered | Data Needs | Decision Impact |
|---|---|---|---|---|
| Descriptive twin | Reflects current asset condition in real time | What is happening right now? | Continuous sensor data | Improves visibility without changing decision timing |
| Diagnostic twin | Connects signals to underlying causes and patterns | Why is this happening? | Historical and contextual data | Reduces time between detection and response |
| Predictive twin | Projects the likely future behavior and failure scenarios | What will happen and when? | Model-driven and historical data | Enables intervention before disruption occurs |
Where Digital Twin Visualization Breaks Down
As digital twins mature into making predictions and informing decisions, their capability depends on how well they model real-world phenomena. The system could be complex, but its predictions are based on the data, logic models, and links feeding the system. Defects in any of these layers can rapidly degrade the quality of predictions
Information quality
The digital twin model needs accurate input at all stages, and many companies struggle with inconsistent data. Incomplete attributes, redundant records, or inconsistent standardization create noise that confuses the system’s capability of understanding behavior. Small errors at this point can grow and decrease confidence in predictions.
Limits of modeling
Models are developed on calibrated assumptions about the asset behavior, and these assumptions need to change as the situation changes. An active model that has gone unmaintained begins to drift away from reality and produce inaccurate predictions. This sort of drift in the model is often unnoticed until an action is executed based on the outputs and produces undesirable outcomes.
Field–level gaps
Sensor misalignment, gaps in coverage, or incomplete asset inventories create blind spots that can’t be modelled around. The system does not catastrophically fail in these cases. When it keeps running with progressively more partial information, it hides risk.
| Where things break | What actually happens | What it does to the system | What it leads to |
|---|---|---|---|
| Poor data quality | The model receives incomplete or inconsistent inputs | The system starts reflecting distorted behavior | Decisions are based on misleading signals |
| Weak integration | Data stays scattered across systems instead of flowing together | The model lacks a full operational context | Actions are delayed or based on partial insight |
| Incorrect modelling | Assumptions no longer match how the asset behaves | Simulations drift away from real-world conditions | Maintenance decisions miss the actual issue |
| Sensor gaps | Parts of the asset are not captured or tracked properly | Blind spots form in the model’s understanding | Early signs of failure go unnoticed |
Business Impact of Digital Twins
AI-powered digital twins transition from capturing asset behavior to shaping how operations are planned, carried out, and fine-tuned over time. It surfaces the link between data and business performance.
Faster Decision Making
Data streams into the system, the model processes it, decisions are made sooner, and actions are taken ahead of disruption. Each link in this chain decreases uncertainty and results in more stability and fewer surprises. Over time, this shift compounds as the system continually learns from prior decisions and results.
Reduced Unplanned Downtime
Problems are detected and resolved before they compromise performance. Maintenance scheduling shifts to reflect the actual condition of assets in place of time-distance-based intervals, which enhances effectiveness and prevents needless interventions. As a result, the teams are spending less time reacting to failures and more time managing performance proactively.
Menores costes de mantenimiento
Maintenance is cheaper as interventions are more focused. Life of assets extends with timely actions. Thus, reactive spending reduces and resource allocation is optimized across operations.
Gestión optimizada del inventario
Inventory decisions also get better, as recambios stock is matched to predicted, rather than uncertain, demand. This depletes surplus inventory and reduces the risk of critical shortages during maintenance periods.
Implementation Challenges with Digital Twins
Many organizations understand the potential of digital twins, but the implementation is delayed because of the cost and complexity. Integrating a digital twin with existing infrastructure is another challenge.
Data Readiness
Data readiness becomes the constraint that make organizations hesitate to deploy a digital twin. Asset records are inconsistent, hierarchy relationships are missing, and data is scattered across multiple systems, all limiting how well the twin can function. Even with the technology, the digital twin can’t deliver dependable results unless it is fed with structured and consistent data. Soluciones Verdantis can standardize data through asset normalization and data harmonization.
Legacy System Integration
Initial deployment may involve investment in sensors, data pipelines, and integration between multiple systems that were never intended to work in concert. This introduces both technical and business complexity, particularly in legacy environments. Although modelling itself is often described as being the hard part, in fact, most of the work is in bringing data sources and systems into line.
Scaling
Early attempts to scale introduce failure because data and integration problems go unaddressed and multiply across assets. A small-scale implementation instills confidence, provides refinement of the system, and develops a duplicatable process for growth.
Most organizations prioritize a single high-value asset for which they have a clearer understanding of the potential impact of failure and where the data can be more easily validated. This enables teams to run data through the motion, validate model performance, and observe how the decisions improve prior to moving more broadly.
AI and the Evolution of Digital Twins
As digital twins proliferate among assets and systems, the volume of data becomes too large to analyze manually. Signals flow nonstop, patterns change in real time, and monitoring evolving changes at scale requires automation that surpasses human capabilities.
The Challenge of Data Scale
The use of connected devices continues to increase, and systems produce huge operational data sets across a wide range of conditions. While this results in more interesting models of equipment behavior, it also creates complexity that cannot be handled by manual approaches. The teams have the data, but the speed of interpretation is the choke point. The Patsnap insights show that closed-loop twins cut downtime by 20% to 40% via real-time optimization.
Pattern Detection and AI
AI compensates for this by detecting minute anomalies, relationships, and signals of degradation that fixed rules do not. Based on historical data (training) and using data collected from past behavior (status and alerts sequences) and events, AI can recognize failures that potentially can be qualified as false positives. This speeds up diagnostics and increases predictive accuracy without additional manual work. Fleets that have adopted AI-driven twins report 75% fewer breakdowns.
Hybrid Physics-AI Twins: Grounded Intelligence
Major organizations integrate physics-based models (known asset behavior) with AI/ML (learned patterns) to create hybrid models. These remain grounded in real-world physics, but they are also dynamic, evolving with data, enabling the following:
Fleet-level learning: Knowledge is shared among hundreds of analogous assets to help isolate common anomalies, thereby magnifying the power of anomaly detection and making it faster and more accurate.
Self-improving accuracy: Models become more refined and accurate predictors as they gain operational history, including autonomous actions such as energy optimization.
By 2030, 15% of process plants will be implementing these closed-loop systems, according to Gartner, as digital twins evolve from using monitoring to making operational decisions. This transformation converts data overwhelm into a tactical advantage for manufacturing uptime and productivity.
Conclusión
A digital twin operates like a feedback loop where data is collected, behavior is modelled, deviations are analyzed, and outcomes can be tested before taking action in the physical world. Each choice is fed back into the system, and this enhances how future signals are deciphered. This transition enables teams to shift from responding to known problems to acting on early fault signals, increasing uptime at a lowered risk of failure.
The true value is in how consistently this loop goes from data to outcomes. Platforms such as Verdantis enable this by harmonizing data quality, asset structure, and system integration to allow decisions to be executed with confidence. This ultimately results in a cumulative advantage where each loop reinforces operational intelligence.
Preguntas más frecuentes (FAQ)
What distinguishes a digital twin from a simulation?
A simulation deals with static assumptions. You set the inputs, run the scenario, and see what comes out. A digital twin does not stay static in that way. It’s continually updated as the real asset runs, so the model evolves with real-world conditions rather than being locked to an initial configuration. It is this difference that enables it to describe not only what could happen, but what is already happening.
What information do you need to create a digital twin?
For a digital twin, you need information about how the asset behaves while it runs. Sensor data, temperature, or vibration readings serve as a starting point. Past performance, asset configuration, and operational context all must be incorporated into the model for it to simulate the asset properly. When that information is missing or fragmented, the twin can still run, but its results are far less reliable.
Can a digital twin accurately predict failures?
Yes, a digital twin can predict failures with high accuracy, but only if the system underneath does. The accuracy of prediction relies on how clean the data is, how well the model represents actual behavior, and whether there is sufficient history to find patterns. When all that infrastructure is in place, the system can make reasonably confident predictions of failure rates and remaining useful life. Even at that point, precision is a steadily increasing function of further operation data feeding back into the model.
What are the main challenges in digital twin implementation?
Most teams struggle with data that is scattered, inconsistent, or poorly structured across systems. Integration takes time, especially when existing platforms were never designed to work together. There is also a practical challenge in getting teams to trust and use the system in daily decisions. All of this means adoption slows down, not because the concept is difficult, but because the environment around it needs alignment.



