












La gestión de datos maestros está pasando de ser una función reactiva basada en reglas a una capacidad estratégica impulsada por la inteligencia.
Los enfoques tradicionales suelen tener dificultades para seguir el ritmo de los datos complejos y multidominio distribuidos en los sistemas ERP, CRM, PLM y SCM, lo que deja a las organizaciones expuestas a errores, duplicados y registros incompletos.
Gartner informa de que la mala calidad de los datos cuesta a las organizaciones una media de $12,9 millones al año. La IA y el aprendizaje automático están transformando este panorama al permitir procesos autónomos como el enriquecimiento de datos, la normalización, la deduplicación y la detección de anomalías.
Estas capacidades permiten a las organizaciones mantener de forma proactiva datos de alta calidad, coherentes y procesables en todos los dominios de clientes, productos y MRO.
Al cambiar la MDM de una tarea impulsada por el cumplimiento a un proceso proactivo habilitado por la IA, las empresas pueden convertir conjuntos de datos anteriormente fragmentados y propensos a errores en una única fuente de verdad, impulsando mejores decisiones operativas, reduciendo el riesgo y desbloqueando nuevas eficiencias en toda la empresa.
CASOS DE USO
Los procesos dentro de la gestión de datos maestros incluyen una amplia gama de flujos de trabajo y procesos en los que se pueden implementar tecnologías centradas en la IA;
Normalización y estandarización de los registros de datos
Enriquecimiento de los registros de datos maestros
Deduplicación
Integraciones entre dominios de datos maestros
Gobernanza de datos maestros
En las secciones siguientes, trataremos cómo las tecnologías de IA pueden abordar algunos de los retos más recurrentes, monótonos y lentos dentro de cada uno de ellos.
Normalización y estandarización de los registros de datos
En los entornos empresariales, un mismo artículo suele describirse de muchas maneras en las distintas plantas, sistemas o regiones, utilizando diferentes abreviaturas, convenciones de nomenclatura, unidades de medida o incluso idiomas.
Esto crea incoherencias que perturban el análisis, la capacidad de búsqueda, la recuperación, la lógica de correspondencia y la colaboración entre funciones.
Algunos de los problemas debidos a estos retos son: dificultad para cotejar conjuntos de datos en masa, duplicación debida a diferentes convenciones de nomenclatura y diversos retos a la hora de implantar un programa de gobernanza de datos.
Uno de los principales retos de la gestión de datos maestros es que los atributos esenciales de los artículos, como las dimensiones, la presión nominal y los grados de los materiales, suelen estar enterrados en descripciones de texto libre o documentos técnicos como PDF, hojas de datos o manuales técnicos, Listas de materiales (listas de materiales) o planos CAD.
Esta naturaleza desestructurada dificulta la extracción, normalización o incluso la búsqueda eficaz de estos registros. La IA y el ML, en particular el Procesamiento del Lenguaje Natural (PLN), desempeñan aquí un papel clave.
Los modelos de PLN entrenados, a menudo mediante el Reconocimiento de Entidades Nombradas (REN), pueden analizar descripciones complejas e identificar automáticamente los atributos clave.
Por ejemplo, una descripción de producto como "Válvula de bola con bridas SS316, PN40, DN25" se desglosaría inteligentemente en: Material = SS316, Presión = PN40, Tamaño = DN25y Tipo = Válvula de bola.
Ejemplos:
En un sistema de datos maestros de clientes, la dirección del cliente A se refiere al estado "Texas" como "TX" y otro registro puede referirse al estado simplemente como "Texas", incoherencias similares en direcciones como "Parkway" referida como "Pk way" son bastante comunes.
En un sistema de datos de materiales, la dimensión en la descripción breve de una pieza de recambio puede referirse al tamaño en "Pulgadaso "En" o simplemente como ″
Cuestiones como éstas pueden dar lugar a un exceso de existencias (en el caso de un maestro de materiales), duplicación en las comunicaciones (en el caso de un maestro de clientes) y toda una serie de problemas adicionales.
Antes de la IA, estos retos se mantenían a través de una biblioteca de taxonomías existentes que, por lo general, no era "holística", era difícil de mantener y rastrear y requería actualizaciones continuas y sólo funcionaba con gestionadas dentro de una base de código estructurada.
Gracias a los modelos de IA "conscientes del contexto" y entrenados en grandes conjuntos de datos verificables, estas incoherencias pueden eliminarse ahora sin mucho esfuerzo sobre la base de la taxonomía adoptada.
El modelo de IA sólo tiene que recibir información sobre la taxonomía que se adopta y el modelo se encarga de los requisitos de normalización.
Consejo profesional: Elija un software MDM de autoaprendizaje que pueda ser entrenado sobre la marcha por el "Human-in-the-Loop" que verifica los cambios y los aprueba.
De este modo, el sistema de autoaprendizaje puede llegar a ser verdaderamente autónomo, limitando el papel del administrador de datos a un aprobador.
1. Ampliación de abreviaturas y correspondencia terminológica: Los modelos de IA entrenados con datos del sector entienden que "Mtr" = "Contador", "SS304" = "Acero inoxidable 304", "CS Ball Vlv" = "Válvula de bola de acero al carbono", etc. Asignan esas variantes a una terminología normalizada.
2. Normalización y conversión de unidades: Si las dimensiones se escriben como "10 mm", "0,01 m" o "3IN X 5 YDS".AI puede convertirlos y unificarlos en el sistema de medida preferido (por ejemplo, métrico), y separar los campos compuestos en atributos estructurados como Anchura y Longitud.
3. Estructuración agnóstica del lenguaje: Los modelos de IA pueden interpretar descripciones en otros idiomas y formatos locales para garantizar la coherencia global.
Por ejemplo: Reconociendo que "Filtros de aceite, 7-1/16 pulg" en español se refiere a un "Filtro de aceite, 7-1/16 pulgadas"y, a continuación, extraerlo y asignarlo correctamente.
Enriquecimiento de los registros de datos maestros
Uno de los problemas más molestos en la gestión de la mayoría de los conjuntos de datos maestros tiene que ver con la falta de información. Esto es a menudo el resultado de prácticas de gobierno de datos maestros ausentes o deficientes en primer lugar. Según Super AGI,
El enriquecimiento de datos con IA puede mejorar la calidad de los datos hasta en 90% y reducir el tiempo de procesamiento hasta en 80%.
La información que falta es difícil de gestionar, ya que la deduplicación, la normalización y las integraciones multidominio se vuelven complicadas si el contexto de un registro de datos simplemente no está disponible en primer lugar.
En el pasado enriquecimiento de los registros de datos se realizaba manualmente por un equipo de especialistas en la materia O mediante automatizaciones complejas que requerían un almacén de datos que debía mantenerse de forma estructurada.
Automatización de edificios en el enriquecimiento de datos requerido anteriormente proveedores de software de datos maestros Crear asociaciones de datos para acceder a catálogos de proveedores, datos de contacto, información sobre empleados, etc., en función del ámbito de datos en cuestión.
Contratar a un equipo de especialistas en la materia es una propuesta bastante costosa. Pero, además, la dificultad de resolver el problema de los datos que faltan también aumenta, lo que provoca más retrasos y agrava la situación. los retos derivados de la mala calidad de los datos maestros.
Los sistemas de IA agenciales resuelven este reto, ya que son «conscientes del contexto» y capaces de ejecutar tareas complejas como navegar por la web, recuperar datos de documentos y otras fuentes no estructuradas y completar los huecos en los registros de datos existentes.
Además, Protocolos MCP avanzan cada día, dotando a los agentes de IA de la información necesaria para poder ejecutar flujos de trabajo tanto rudimentarios como complejos mediante el uso de software de terceros.
De esta manera, los agentes de IA entrenados específicamente para este fin, cuando cuentan con los recursos adecuados, pueden resolver de forma autónoma casi todos los retos relacionados con el enriquecimiento de datos, y en una fracción del tiempo necesario.
En el caso de documentos escaneados o archivos de planos de ingeniería, los sistemas de IA utilizan el reconocimiento óptico de caracteres (OCR) combinado con el reconocimiento de patrones para extraer datos tabulares o especificaciones, incluso cuando aparecen en imágenes o planos de ingeniería.
Esto permite a las organizaciones extraer datos de documentos técnicos y transformarlos en registros de datos maestros limpios, estructurados y con capacidad de búsqueda.
Algunas aplicaciones de los agentes de IA en el enriquecimiento de datos maestros
Aplicaciones
1. Análisis automático de atributos a partir de descripciones
Los modelos de IA, en particular los basados en PNL y entrenados en conjuntos de datos específicos del sector, pueden extraer de forma inteligente datos estructurados de descripciones de productos o materiales complejas y no estructuradas.
Ejemplo: Conversión de "3-11/16″OD ,7-1/16″LG" en campos estructurados como Diámetro exterior y Longitud en los registros maestros de materiales.
2. Comprensión semántica para la asignación de campos
La IA entiende el contexto de las palabras y abreviaturas utilizadas en los distintos sectores (por ejemplo, "LG" = Longitud, "OD" = Diámetro exterior) y las asigna a campos de datos normalizados.
Ejemplo: Reconocer que "BALDWIN 915" se refiere a un fabricante y a un número de pieza, y asignarlos en consecuencia.
3. Armonización y conversión de unidades
La IA estandariza los diferentes formatos y representaciones de las mediciones en un formato unificado en todo el conjunto de datos, eliminando incoherencias.
Ejemplo: Conversión de "3IN X 5 YDS" a unidades métricas estandarizadas y división en unidades separadas Anchura y Longitud
La falta de información, como especificaciones, números de pieza del fabricante o unidades de medida, es un problema habitual, especialmente en conjuntos de datos heredados o importaciones de terceros.
Estas deficiencias pueden obstaculizar los flujos de trabajo relacionados con las adquisiciones, el cumplimiento normativo y el análisis.
La IA y el ML ofrecen formas inteligentes de rellenar estos espacios en blanco. Mediante técnicas como la inferencia basada en similitudes, los modelos escanean los registros completos existentes para sugerir valores probables para los incompletos.
Por ejemplo, Si un nuevo artículo «Rodamiento SKF 6205» no tiene indicado su diámetro exterior, la IA puede deducir el valor (por ejemplo, 52 mm) a partir de otros artículos idénticos o similares que ya se encuentran en la base de datos.
Además, la inteligencia artificial generativa puede cruzar datos internos con catálogos externos o bases de datos de proveedores para obtener detalles enriquecidos, como dimensiones, hojas de datos, datos del ciclo de vida o piezas alternativas.
Los modelos predictivos, como los algoritmos de regresión o los árboles de decisión, también pueden utilizarse para estimar campos numéricos como la tensión, el par o la presión nominal cuando no se mencionan explícitamente.
Este nivel de enriquecimiento garantiza unos datos maestros más completos y utilizables, minimiza la introducción manual de datos y respalda los esfuerzos posteriores de automatización, abastecimiento y cumplimiento.
Es bastante habitual, especialmente en el dominio de datos maestros de clientes, encontrar casos en los que falta un registro de datos, como una dirección de correo electrónico, un número de teléfono o una dirección.
Mediante una combinación de protocolos MCP y agentes de IA, esta información que falta se puede enriquecer recuperando datos de fuentes públicas como LinkedIn e incluso de fuentes de terceros basadas en suscripciones como DnB o ZoomInfo.
Actualmente, se está aplicando cada vez más un enfoque similar a los datos sobre repuestos y MRO, donde la falta de información o la inconsistencia de los datos pueden afectar gravemente al rendimiento del mantenimiento y la cadena de suministro.
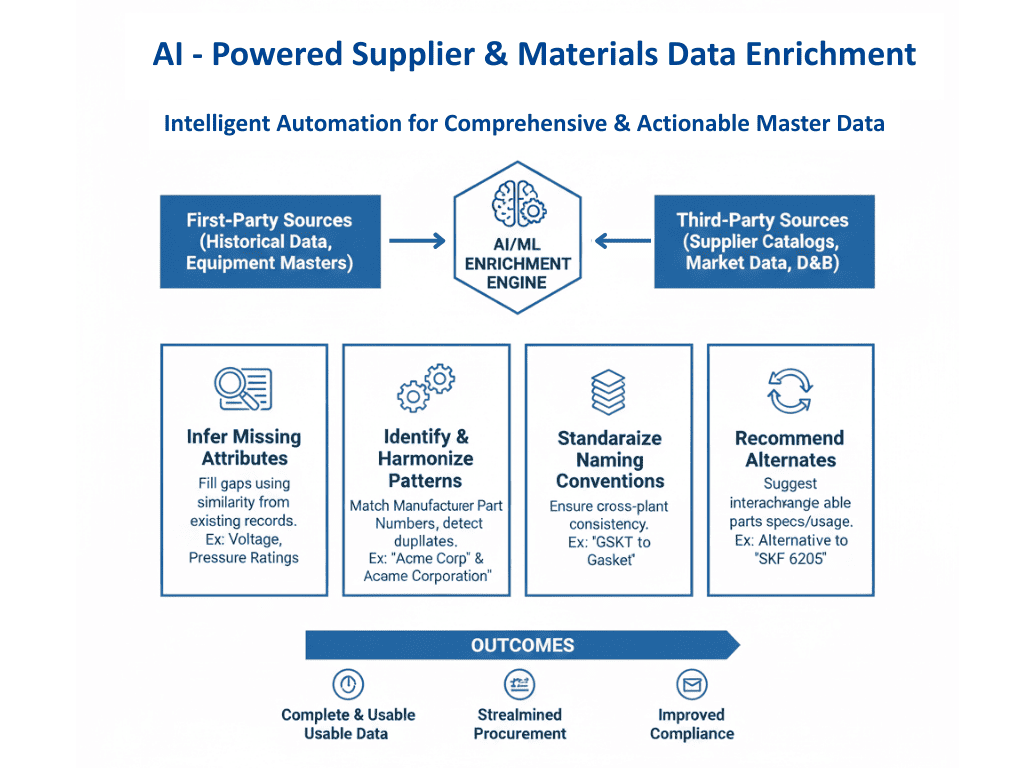
Los datos sobre piezas de repuesto suelen adolecer de descripciones incompletas, atributos técnicos que faltan o entradas duplicadas repartidas por múltiples sistemas. Esto provoca confusión durante la búsqueda de piezas, retrasos en el mantenimiento y compras redundantes.
El enriquecimiento de datos basado en IA ayuda a abordar estos retos haciendo que los registros de piezas de recambio sean más completos, coherentes y procesables.
Mediante el análisis de registros de equipos, catálogos de proveedores y datos históricos, los sistemas de IA pueden:
1. Inferir los atributos que faltan. como el tipo de pieza, la calidad del material o las especificaciones de funcionamiento.
Por ejemplo, en los datos sobre materias primas para plantas químicas, la IA puede inferir los niveles de pureza, los códigos de peligro o las instrucciones de almacenamiento que faltan comparando materiales similares en la base de datos.
2. Identificar los patrones del fabricante y el número de pieza. para la armonización entre proveedores.
En los catálogos de compras, la IA puede detectar SKU duplicados que existen con nombres o códigos de proveedor ligeramente diferentes, lo que ayuda a evitar pedidos redundantes.
3. Estandarizar las convenciones de nomenclatura. para la coherencia entre plantas.
Por ejemplo, en los datos maestros de productos, la IA puede identificar categorizaciones incoherentes, como un smartphone incluido en la categoría «Accesorios» en lugar de «Dispositivos móviles», y corregirlo para garantizar la coherencia de los informes y los análisis.
Según un Informe de Gartner,
Prioridades en materia de gobernanza de la calidad de los datos: se observa que las incoherencias entre silos (falta de coherencia, exhaustividad y unicidad de los registros) se encuentran entre los problemas más difíciles de resolver para las grandes empresas.
4. Recomendar piezas intercambiables o alternativas. basándose en la similitud de las especificaciones, el uso o los datos históricos de consumo.
Por ejemplo, si un registro solo incluye «GSKT, 4BOLT, SS316», La IA puede reconocerla como una junta de acero inoxidable, identificar su tipo de brida e incluso sugerir alternativas compatibles en stock o de proveedores autorizados.
Esta visión enriquecida de los datos sobre repuestos y productos mejora la planificación del mantenimiento, agiliza las compras y permite optimizar el inventario, especialmente en operaciones con múltiples plantas, donde la visibilidad de las piezas o la coherencia del maestro de productos suelen estar fragmentadas entre los distintos centros.
A continuación se muestra nuestro vídeo del producto, en el que se muestra cómo nuestra solución de agencia enriquece los datos procedentes de fuentes propias y de terceros:
Deduplicación de datos
Gartner informa que la mala calidad de los datos le cuesta a las organizaciones un promedio de $12,9 millones al año.
Una vez que los registros de datos se han estructurado, normalizado, estandarizado y enriquecido con la ayuda de la IA, la deduplicación de datos se convierte en una tarea muy sencilla.
El proceso de deduplicación en sí mismo no utiliza mucha IA (excepto en el caso de los duplicados L2), pero los pasos previos son fundamentales para garantizar una deduplicación precisa en todo el conjunto de datos.
Las entradas duplicadas en un conjunto de datos maestros se clasifican normalmente en dos categorías: L1 y L2.
La deduplicación L1 es sencilla y directa; en este caso, todo el conjunto de datos se deduplica basándose en una única lógica.
Ejemplo 1: El mismo ID de material en caso de materiales directos.
Ejemplo 2: La misma dirección de correo electrónico o número de teléfono en el caso de los datos maestros de un cliente
Ejemplo 3: El mismo número de socio fabricante (NPF) en caso de Piezas de repuesto MRO datos.
Esencialmente, cualquier registro de datos con los mismos valores en una propiedad que identifica irrefutablemente el registro como una entrada duplicada es un duplicado L1.
Apenas hay IA que pueda utilizarse aquí, ya que la lógica está estandarizada y estructurada.
Esta es la razón por la que el enriquecimiento de datos maestros suele ser un precursor de la desduplicación de datos maestros, ya que el enriquecimiento permite actualizar varios valores en el sistema, que luego pueden aprovecharse para la desduplicación L1.
Los duplicados L2, en cambio, son mucho más complejos y suelen utilizarse cuando faltan los valores necesarios para aplicar la lógica L1.
La IA simplemente no ha evolucionado lo suficiente como para automatizar completamente la detección de duplicados L2.
Dicho esto, la IA puede hacer el trabajo mucho más simple, club probables duplicados mediante el escaneo de todo el registro de datos y el propio conjunto de datos antes de asignar un "puntuación de confianza por duplicado", que luego puede asignarse como tarea a un revisor humano para que "acepte" o "rechace" los registros de datos como duplicados.
Después de que el administrador de datos "acepte" los registros de datos, generalmente se fusionan, en lo que los datos de los 2nd después de crear los campos en el primer registro.
A continuación se muestra un vídeo en el que se muestra cómo nuestro agente de IA deduplica los datos:
Integración de datos maestros para el éxito multidominio
Una de las críticas más conocidas a un sistema de datos maestros es el hecho de que cada conjunto de datos maestros, en la práctica, existe aislado de los demás en sistemas de organización dispares.
Para comprender realmente el rendimiento de cualquier función organizativa, es crucial interpretar los datos en todos los dominios de datos maestros.
Ejemplo 1: Es importante saber a cuántos clientes se puede llegar a través de cualquier canal de comunicación de marketing, pero también es importante saber qué productos favorecen más estos consumidores, lo que requiere integraciones profundas con datos maestros de productos
Ejemplo 2: Es importante saber cuántos recambios hay en la plataforma de aprovisionamiento para aprovisionar las actividades de producción, pero también es más importante saber cuáles de estos recambios son necesarios para el mantenimiento de los activos críticos, que serán los siguientes las piezas de recambio críticas.
Esto sólo es posible con una profunda integración de los datos del maestro de activos con el maestro de materiales de las piezas de recambio.
Gobernanza de datos
Gobernanza de datos maestros tienen por objeto garantizar que los datos maestros sean precisos, seguros, normalizados y conformes con las políticas internas y la normativa externa.
Sin embargo, a medida que los volúmenes de datos crecen y se vuelven más complejos en los sistemas distribuidos (ERP, PLM, CRM, SCM, etc.), la aplicación manual de las políticas de gobernanza se vuelve inescalable y reactiva.
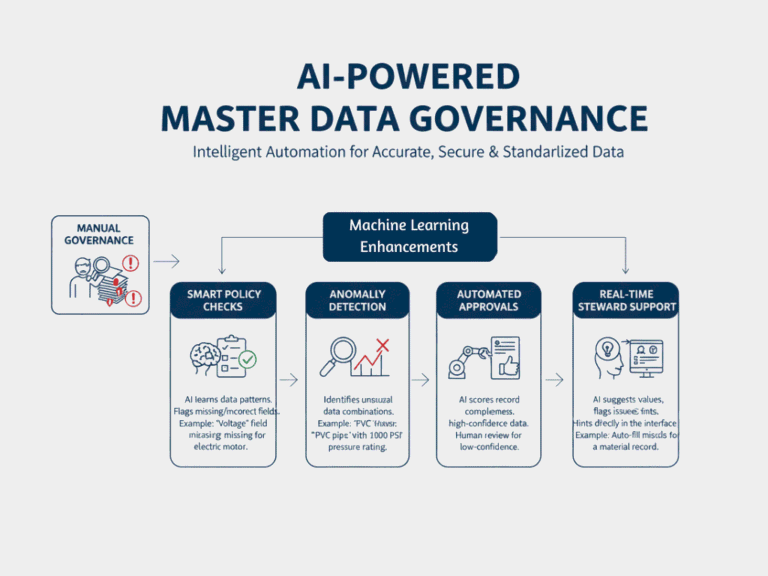
El aprendizaje automático aporta una automatización proactiva e inteligente a las principales funciones de control de datos al permitir la aplicación dinámica de políticas, la detección de anomalías y el apoyo inteligente a la toma de decisiones.
Estos modelos pueden supervisar y mejorar continuamente la calidad de los datos, al tiempo que reducen la carga manual de los administradores de datos.
Aplicaciones:
1. Comprobación inteligente de políticas
La IA aprende qué aspecto suelen tener los registros limpios y aprobados, y comprueba si faltan campos o son incorrectos en las nuevas entradas, aunque no haya ninguna norma establecida.
Por ejemplo: Si la mayoría de los registros de motores eléctricos tienen rellenado el campo "Tensión" y un nuevo registro no lo tiene, la IA lo marca de inmediato.
La IA examina registros anteriores, aprende qué campos van juntos y utiliza ese conocimiento para detectar errores.
2. Detección de anomalías y errores
Los modelos ML detectan valores o combinaciones inusuales en los datos que no se ajustan a los patrones normales.
Por ejemplo: Una "tubería de PVC" con "1000 PSI" está marcada, porque el PVC no suele soportar tanta presión.
La IA se hace una idea de lo que es normal para cada tipo de artículo y detecta los valores atípicos mediante modelos de reconocimiento de patrones como los bosques de aislamiento o los autocodificadores.
3. Aprobación automatizada de registros
La IA puntúa los registros nuevos o actualizados en función de su limpieza y exhaustividad. Los registros de alta confianza pueden aprobarse automáticamente, mientras que los de baja confianza se envían a un humano para su revisión.
Por ejemplo: Un artículo clasificado como "Perno hexagonal", con todos los campos rellenados correctamente y que coincide con los datos anteriores, se aprueba automáticamente.
Los modelos ML calculan una puntuación de confianza en función del grado de coincidencia del registro con las normas existentes.
4. Ayudar a los administradores de datos en tiempo real
La IA ayuda a los administradores de datos mientras trabajan sugiriendo valores, señalando campos que faltan o indicando posibles problemas.
Por ejemplo: Al revisar un registro de material, un administrador ve sugerencias de IA para los campos que faltan y recibe alertas si algo no coincide con entradas similares.
Los modelos NLP y ML se ejecutan en segundo plano y muestran sugerencias y advertencias inteligentes directamente en la interfaz.
A continuación se exponen algunos casos de uso:
Datos maestros de clientes:
En las grandes empresas multinacionales, los nuevos registros de clientes suelen llegar a través de múltiples canales, portales CRM, envíos de socios o cargas internas.
La falta de direcciones de correo electrónico, NIF o información de facturación incompleta puede retrasar la facturación y crear riesgos de cumplimiento. Los sistemas de gobernanza de IA detectan automáticamente los campos obligatorios que faltan, los enriquecen utilizando fuentes internas y externas verificadas y señalan los posibles duplicados en el punto de entrada.
Por ejemplo, si dos registros muestran "Acme Corp" y "Acme Corporation", el sistema señala un posible duplicado y evita entradas redundantes. De este modo se garantiza una altadatos de calidad sobre los clientes al tiempo que se reduce el esfuerzo manual.
Datos de materiales y repuestos:
En el ámbito de los materiales o MRO, es habitual que falten especificaciones, números de pieza del fabricante o información sobre unidades de medida, especialmente en conjuntos de datos heredados o importaciones de terceros.
Estas lagunas dificultan el aprovisionamiento, la planificación del mantenimiento y los flujos de trabajo analíticos. El enriquecimiento basado en IA puede inferir valores que faltan a partir de registros existentes, cruzar catálogos de proveedores y estandarizar convenciones de nomenclatura en varias plantas.
Por ejemplo, un nuevo registro "Rodamiento SKF 6205" al que le falte su diámetro exterior puede enriquecerse automáticamente con el valor correcto a partir de elementos similares de la base de datos.
Del mismo modo, un registro catalogado como "GSKT, 4BOLT, SS316" puede enriquecerse para especificar una junta de acero inoxidable, identificar el tipo de brida y sugerir alternativas compatibles.
Los modelos predictivos, como los algoritmos de regresión o los árboles de decisión, también pueden estimar campos numéricos como la tensión, el par o la presión nominal cuando no se dispone de valores explícitos.
Al identificar anomalías, armonizar números de pieza, normalizar descripciones y sugerir alternativas, la IA garantiza que el maestro de materiales se convierta en una fuente de verdad fiable y procesable.
A continuación encontrará nuestro vídeo sobre la solución de gobierno de datos de Verdantis:
Diseño e implantación de la IA en MDM
Aunque las ventajas del aprendizaje automático en la gestión de datos maestros son evidentes, su adopción satisfactoria requiere una integración meditada con la arquitectura empresarial y los modelos de gobernanza:
Calidad de los datos de formación: El rendimiento de los modelos de IA/ML está directamente ligado a la calidad y representatividad de los datos históricos utilizados para entrenarlos.
Contexto específico del ámbito: Los modelos estándar suelen requerir un ajuste o reajuste para adaptarse a los matices específicos de los datos de ingeniería, fabricación o aprovisionamiento.
Explicabilidad y confianza: Los usuarios deben poder rastrear y comprender cómo la IA ha llegado a una decisión o sugerencia concreta, especialmente en los sectores regulados.
Human-in-the-Loop (HITL): Los sistemas de IA deben diseñarse para aumentar y no sustituir a los administradores de datos, permitiendo la supervisión humana cuando sea necesaria y creando circuitos de retroalimentación para la mejora continua.
Conclusión
La IA y el ML no solo están mejorando la gestión de datos maestros, sino que están redefiniendo lo que es posible. Estas tecnologías aportan un nivel de velocidad, adaptabilidad e inteligencia que los sistemas manuales y basados en reglas no pueden igualar.
Para MDM, la gestión de datos MRO y la gobernanza de datos, la IA ya no es un concepto emergente, sino una capacidad necesaria para aumentar la calidad de los datos, acelerar la toma de decisiones y preparar las operaciones empresariales para el futuro.
A medida que las organizaciones sigan adoptando la transformación digital, aquellas que integren la inteligencia impulsada por la IA en sus prácticas de datos maestros estarán mejor posicionadas para operar con agilidad, precisión y conocimiento.



