












Comparación del mejor software y los mejores proveedores para la limpieza de datos
Para que cualquier sistema de software o proceso organizativo funcione sin trabas, la calidad de los datos subyacentes es igual de importante, si no más, que la de los propios sistemas técnicos y plataformas de software que dependen de los datos para la continuidad y precisión de las operaciones empresariales.
Desgraciadamente, sin embargo, la disponibilidad y preparación de las organizaciones para mantener la calidad de los datos y aumentarla no ha seguido el mismo ritmo en comparación con otras tecnologías.
Desde 2021, inmediatamente después del primer anuncio público de la plataforma de IA conversacional, ChatGpt, y la posterior presentación de sistemas agénticos que pueden ejecutar de forma autónoma un sinfín de tareas, el debate sobre la calidad de los datos vuelve a estar en la mente de todos.
Esto es especialmente cierto cuando las empresas se han dado cuenta de que incluso los mejores sistemas tecnológicos son inútiles o imprecisos cuando los datos subyacentes están incompletos, duplicados, no son fiables y no están sincronizados con otros sistemas de gestión de datos.
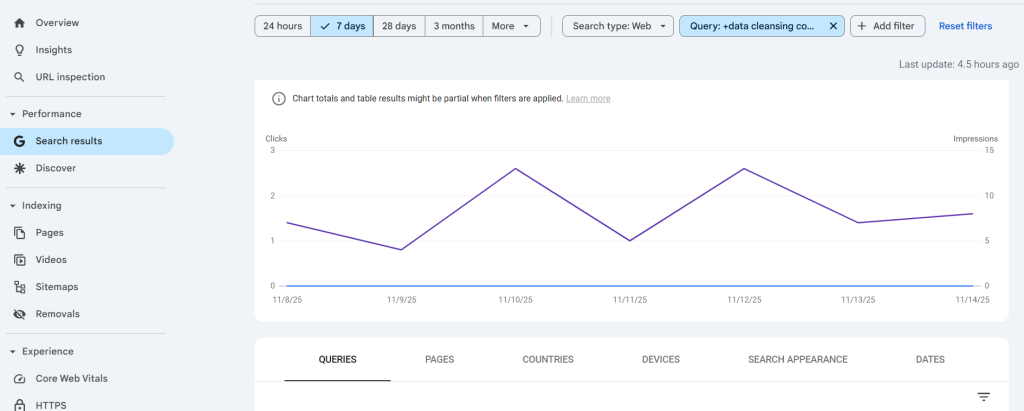
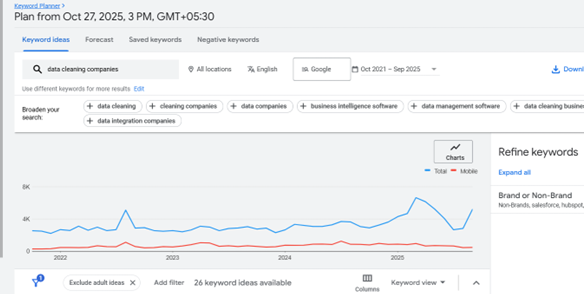
El siguiente gráfico muestra un repunte en el número de búsquedas de usuarios que buscan explorar servicios y herramientas de limpieza de datos para garantizar unos umbrales de calidad de datos permanentes.
Para que los compradores, los profesionales de la contratación y los equipos de gestión de datos y GTM dispongan de la información adecuada, este artículo recopila algunas de las principales plataformas de limpieza de datos, clasificadas a grandes rasgos en las siguientes categorías.
- Software de limpieza de datos CRM
- Software de limpieza de datos ERP
- Depuración de datos de empleados y RRHH
- Limpieza puntual de datos [Personalizada]
#1, #2 & #3 de los anteriores son requisitos comunes y recurrentes, especialmente en ausencia de marcos de gobernanza de datos deficientes.
Sin embargo, #4 son requisitos de limpieza de datos únicos y puntuales, de naturaleza personalizada y normalmente no recurrentes, ya que se asumen por proyecto.
Además, esta lista incluirá una amplia gama de plataformas de herramientas de limpieza de datos, como herramientas ETL, software de limpieza específico, plataformas de código abierto, software de preparación de datos, etc.
Además, dado que la limpieza de datos es un término amplio, las herramientas detalladas en este artículo se evalúan en función de sus capacidades en;
- Normalización de registros de datos en un formato estructurado a partir de uno no estructurado
- Validación de datos
- Enriquecimiento de los registros de datos
- Deduplicación
- Integración con conjuntos de datos y sistemas tecnológicos relacionados
Herramientas de limpieza de datos CRM
La mayoría de las empresas con más de un millón de $ de ingresos suelen utilizar un sistema CRM. El objetivo del CRM es captar las etapas del recorrido de clientes potenciales, clientes potenciales, oportunidades y clientes a través del ciclo de conversión y dotar a los equipos de ventas, marketing y operaciones de los datos adecuados.
Algunos CRM incluso capturan datos de socios y asociaciones entre socios, clientes potenciales y cuentas objetivo.
Sin embargo, estos datos se erosionan con el tiempo, ya que la duplicación, la falta de información, las asociaciones erróneas de datos son comunes con los equipos de comercialización y de negocios, y no siempre se mantienen las mejores prácticas en la administración de datos.
Openprise
Openprise se comercializa como una plataforma de orquestación y automatización de datos diseñada para ayudar a las empresas a gestionar, limpiar y unificar sus datos en los sistemas de marketing, ventas y operaciones.
El punto fuerte del software es su perfecta integración en múltiples sistemas GTM, como CRM, ERP, plataformas de datos de clientes (CDP), plataformas publicitarias y otras herramientas de terceros para la divulgación y la recopilación de información.
La siguiente imagen muestra cómo OpenPrise potencia las operaciones de ingresos, el marketing de resultados y los equipos empresariales con datos limpios, precisos y fiables.
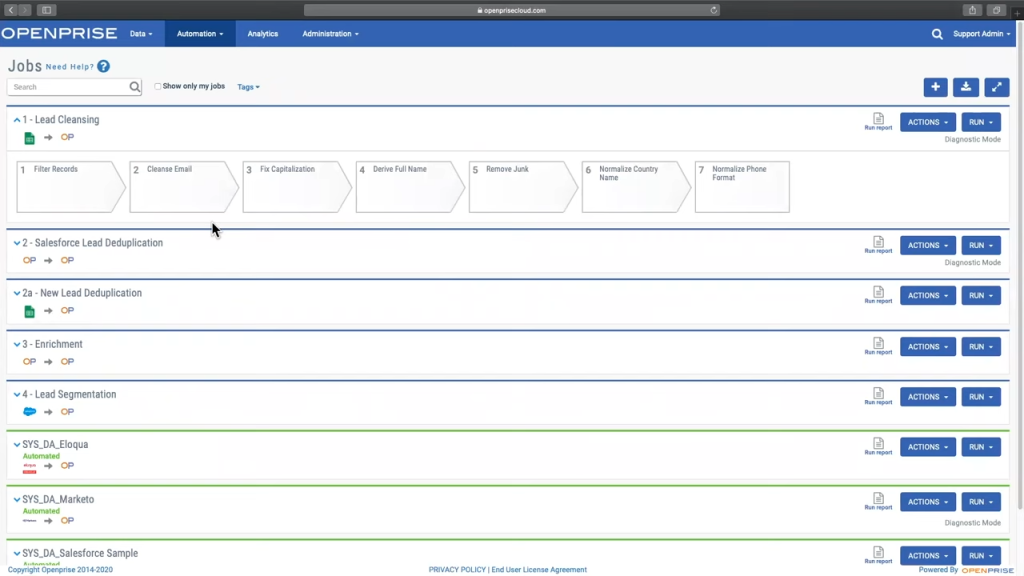
A grandes rasgos, éstas son algunas de sus principales funciones.
- Eliminación de duplicados a nivel de contacto y cuenta, aprovechando la dirección de correo electrónico, los dominios de sitios web, los patrones semánticos y la intervención humana.
- Validación de direcciones de correo electrónico y números de teléfono para eliminar los valores basura
- Normalización de direcciones y códigos postales,
- Inferir datos de localización a partir de números de teléfono
- Inferir datos de ciudad o estado a partir del código postal o viceversa
- Normalización de valores y formatos: por ejemplo: Mayúsculas para los nombres, minúsculas para los correos electrónicos, etc.
- El enriquecimiento de los valores que faltan también es posible mediante la integración de soluciones de inteligencia de contacto de terceros
Además de la limpieza de datos, Openprise también ofrece algunas soluciones para asignar clientes potenciales mediante puntuación y dirigirlos al propietario correspondiente.
Reseñas:
Lista de datos
DataBlist se posiciona como una herramienta práctica de calidad de datos y preparación de listas dirigida a equipos que manejan regularmente conjuntos de datos basados en hojas de cálculo, como listas de contactos, registros de clientes, catálogos de productos o clientes potenciales generados por eventos.
La plataforma se centra principalmente en ayudar a los usuarios empresariales a limpiar, estructurar y normalizar grandes volúmenes de datos sin necesidad de soporte informático ni ningún tipo de programación técnica o código pesado.
Su punto fuerte es ofrecer un espacio de trabajo familiar, de tipo cuadrícula, en el que los usuarios pueden revisar rápidamente los registros, aplicar correcciones y armonizar valores antes de cargar los datos en sistemas CRM, de marketing u operativos.
La siguiente imagen muestra cómo Datablist detecta los duplicados y otras anomalías en los conjuntos de datos
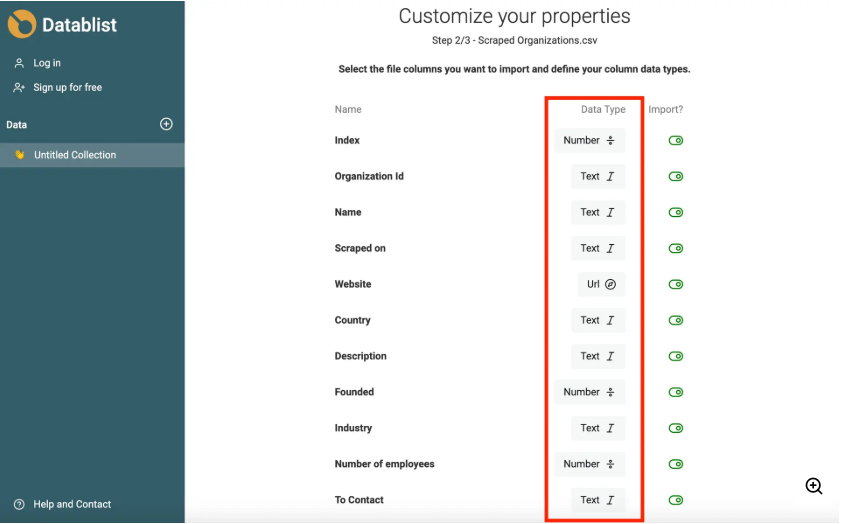
A un alto nivel, DataBlist ofrece un conjunto de capacidades prácticas que ayudan a los equipos a limpiar y preparar las listas antes de trasladarlas a sus sistemas operativos.
- Detecta duplicados en nombres, correos electrónicos, números de teléfono y campos de empresa, lo que permite a los usuarios revisar y combinar registros de forma limpia.
- Marca los correos electrónicos no válidos, los formatos de teléfono incorrectos y los valores obligatorios que faltan para reducir los errores de carga en los sistemas CRM y de marketing.
- Normaliza las mayúsculas, los formatos de teléfono y correo electrónico y otros campos incoherentes en las listas importadas.
- Admite el enriquecimiento basado en búsquedas y reglas sencillas para rellenar los estados, clasificaciones o campos relacionados que falten.
- Divide las direcciones largas, corrige las combinaciones erróneas de ciudad y código postal y asigna los códigos postales a los estados.
- Ayuda a asignar y alinear columnas al consolidar listas de socios, eventos o sistemas antiguos.
- Permite transformaciones masivas y actualizaciones condicionales con un paso de vista previa para evitar sobrescrituras accidentales.
- Se utiliza como una capa de puesta en escena para garantizar que los datos entran en Salesforce, HubSpot, herramientas de divulgación, sistemas de adquisición y plataformas de informes de forma limpia y coherente.
En general, la plataforma ofrece a los equipos de operaciones y RevOps un entorno práctico para revisar, corregir y estructurar sus datos de modo que se trasladen sin problemas a los sistemas que dependen de ellos.
Reseñas:
Limpieza de datos maestros de ERP
Un sistema ERP suele ser utilizado sobre todo por empresas y es mucho menos común que un sistema CRM.
Normalmente, un sistema ERP no coexiste con un CRM, puesto que ya capta la mayor parte de la finalidad prevista de un sistema CRM. Aunque esto no tiene por qué ser necesariamente así.
Un sistema ERP es también mucho más amplio en su alcance y ni siquiera puede compararse con un CRM.
Los sistemas ERP y EAM gestionan todas las funciones, incluida la planificación de la producción, los recursos humanos, la gestión financiera y la contabilidad, además de las operaciones específicas del mercado.
Estos sistemas suelen utilizarse en las cuentas de las empresas, donde el volumen total de registros suele ser bastante grande y disperso, lo que hace que el ejercicio de limpieza de datos sea mucho más complicado.
Los tipos de limpieza de datos cambian de vez en cuando.
- Limpieza de datos "Material
- Depuración de datos maestros de "clientes
- Depuración de datos de "proveedores
- Depuración de datos "Servicios
- Depuración de los datos "Inmovilizado
Verdantis MDM Suite
Verdantis se especializa en soluciones de software para empresas, en particular para organizaciones con un uso intensivo de activos. La suite MDM de Verdantis es un software diseñado específicamente para gestionar la calidad de los datos maestros en dominios de datos específicos de los datos de producción.
El software se entrena en registros de datos específicos de los sectores que se indican a continuación y despliega IA agéntica para corregir las lagunas en la calidad de los datos en todos los dominios de datos maestros.
Los dos módulos disponibles en la suite Verdantis MDM son Harmonize e Integrity;
Armonice: Este módulo se centra en la normalización, limpieza y enriquecimiento de los registros de datos maestros heredados, recopilándolos no sólo de los sistemas ERP o EAM, sino también de múltiples fuentes no estructuradas como facturas de proveedores, listas de materiales de activos, fuentes de inteligencia de terceros como D&B, ZoomInfo, etc.
Integridad: Como su nombre indica, Integrity es un módulo que resuelve la gobernanza de los datos maestros, abarcando los mismos dominios de datos mencionados anteriormente. Este módulo se integra con los ERP de entorno único o múltiple, la pila de datos maestros o los sistemas EAM para crear un proceso y gestionar cada entrada de registro de datos maestros en la propia fuente.
El módulo Integridad está diseñado para garantizar;
- Se reduce drásticamente el tiempo necesario para crear un registro de datos maestros.
- La exactitud y exhaustividad (integridad) del conjunto de datos maestros se mantiene a medida que se crean los registros de forma continua.
La idea que subyace a los datos maestros, los ERP y la excelencia operativa, en general, es reducir el tiempo de ejecución de las tareas y la introducción de datos, la administración son funciones que requieren muchos recursos, especialmente en términos de capital humano.
Para reducir este problema, Integrity se sincroniza con otros módulos de la empresa y valida la creación de registros en tiempo real, señalando posibles duplicados y la falta de información obligatoria.
También va un paso más allá y despliega agentes de IA para autocompletar la información que falta a partir de fuentes de terceros verificadas, como catálogos de proveedores, bases de datos, software de inteligencia e incluso listas actualizadas de sitios web.
El siguiente vídeo muestra cómo funciona Integrity dentro del paquete MDM de Verdantis para gestionar la creación de registros y controlar los registros de datos maestros de la empresa de forma continua.
Ataccama UNO
Ataccama es una plataforma unificada de gestión de datos creada para las empresas que desean aunar la gestión de datos maestros (MDM), la calidad de los datos, la gobernanza y la automatización bajo un mismo techo.
Su oferta principal, Ataccama ONE, es una solución integrada que no solo admite MDM, sino también la creación de perfiles de datos, la observabilidad, el linaje, los datos de referencia y la automatización basada en IA agéntica.
El siguiente vídeo le mostrará las principales funciones de Ataccama:
Ataccama ONE se estructura en torno a capacidades modulares, siendo las dos más destacadas:
- Calidad de los datos y observabilidad: El módulo automatiza la creación de perfiles de datos, las comprobaciones de calidad basadas en IA y la supervisión en tiempo real. Detecta anomalías, sugiere soluciones y facilita la limpieza y el enriquecimiento en todos los dominios de datos clave.
- Gestión de datos maestros: El módulo MDM crea registros maestros gobernados y fiables en todos los dominios. Se integra con los ERP y los sistemas empresariales para gestionar la creación, el enriquecimiento, la aprobación y la publicación, utilizando la concordancia unificada y la deduplicación para mantener un registro de oro coherente y de confianza.
El objetivo de este módulo es bastante sencillo:
Reducir el tiempo y el trabajo manual necesarios para crear o actualizar registros maestros
Mantener los datos exactos, completos y debidamente validados.
Proporcionar una visibilidad clara de quién ha cambiado qué y cuándo, mediante el seguimiento del linaje y la aprobación.
Para que esto funcione, Ataccama ONE comprueba en tiempo real cada registro nuevo o entrante. Si falta algo, está duplicado o tiene un formato incorrecto, el sistema lo marca antes de que los datos se guarden en los sistemas posteriores.
Ataccama trabaja con empresas de los sectores BFSI, telecomunicaciones, farmacéutico y gubernamental, con clientes destacados como Aviva, UniCredit, T-Mobile, Roche y Philip Morris International.
Reseñas:
ODM SAP
SAP es sin duda el pionero en la gestión de datos maestros de ERP. MDG, abreviatura de master data governance (gobernanza de datos maestros), fue lanzada por SAP en 2010 y resuelve los requisitos de las empresas para mantener la calidad de los datos maestros.
Uno de los mayores argumentos de venta de SAP MDG es el soporte del ecosistema para extraer y cotejar los datos de sistemas específicos de SAP. Los usuarios pueden extraer o integrar directamente MDG con sus SAP-ERP, EAM, SAP PM y toda una plétora de software nativo de SAP.
Dicho esto, existen algunas limitaciones con SAP MDG que dificultan que las empresas lo implementen para sus requisitos de datos maestros.
- Funciones limitadas de IA y automatización
Con el modo "Central Governance" en SAP S/4HANA (Feature Pack Stack 2) y las ediciones de nube privada, MDG admite indicaciones en lenguaje natural para realizar cambios en los campos y puede generar automáticamente resúmenes de los cambios.
SAP ha presentado Joule, un asistente/copiloto generativo de IA creado para las aplicaciones en la nube de SAP. Se basa en datos empresariales, es compatible con el lenguaje natural y tiene capacidades de "agente" autónomo.
A pesar de estos anuncios, los casos prácticos de uso de las funciones específicas de IA en SAP MDG parecen limitados, en el momento de escribir este post.
Aunque se están promoviendo los agentes de IA, en los ODM la autonomía de los agentes (es decir, agentes totalmente autónomos para la toma de decisiones en los ODM) sigue siendo algo limitada. Por ejemplo, la Lista de funciones de G2 muestra que para "Agentic AI - Autonomous Task Execution / Multi-step Planning / Adaptive Learning" no hay "Datos suficientes".
- Las integraciones que no son SAP pueden resultar complejas y costosas
Dependiendo de la naturaleza del negocio y de la industria, los requisitos de datos maestros en cualquier empresa dependen en gran medida del "Dominio de Datos" en cuestión.
Una empresa con operaciones intensivas en activos, por ejemplo, requerirá capacidades avanzadas de limpieza de datos, en los dominios de datos de Materiales, Activos Fijos (equipos) y Proveedores.
Del mismo modo, una empresa específica de "SaaS" o "Servicios" puede necesitar capacidades avanzadas de limpieza de datos en los dominios de datos de "servicios" y "clientes".
Para crear estas capacidades y recuperar datos, se necesita un sincronización bidireccional y esto puede ser bastante complejo y costoso con sistemas que no sean SAP.
- El desarrollo de dominios personalizados es complejo
SAP MDG proporciona un sólido soporte listo para usar para dominios de datos maestros clave como Business Partner, Material y Finanzas.
Sin embargo, cuando las organizaciones necesitan gestionar dominios de datos adicionales o específicos del sector -por ejemplo, Activos, Proyectos, Ubicaciones o Equipos-, a menudo se enfrentan a una importante complejidad de implantación.
- Inteligencia de calidad de datos integrada limitada
Aunque SAP MDG proporciona reglas de validación y derivación de datos, carece de algoritmos avanzados de limpieza de datos o de correspondencia.
Las empresas pueden necesitar SAP Data Services (BODS), SAP Information Steward o herramientas de terceros (como Informatica o Trillium) para una verdadera limpieza, enriquecimiento y detección de duplicados de datos.
Ejemplo: La detección de "clientes duplicados" con ligeras variaciones de nombre puede requerir un motor externo de calidad de datos.
Categoría | Puntos fuertes | Limitaciones |
Integración | Excelente con el entorno SAP | Débil con sistemas no SAP |
Gobernanza de datos | Funciones y flujos de trabajo sólidos | Puede provocar cuellos de botella en los procesos |
Calidad de los datos | Validaciones básicas | Carece de funciones avanzadas de limpieza o IA |
Personalización | Gran flexibilidad | Complejo y lento |
Coste y esfuerzo | Fiabilidad de nivel empresarial | Alto coste total de propiedad y tiempo de instalación |
Experiencia del usuario | Mejorado con Fiori | Sigue siendo complejo para usuarios ocasionales |
Reseñas:
Herramientas ETL/Transformación de datos
El software ETL es estupendo para la limpieza de datos no estructurados, sobre todo cuando se trata de tareas puntuales en las que no existen marcos basados en la formación ni modificadores de diccionario.
ETL son las siglas de Extract, Transform & Load (extraer, transformar y cargar). En pocas palabras, el software extrae datos de múltiples fuentes de terceros. Ya sea a través de conexiones API o integraciones listas para usar.
El siguiente paso es la transformación. En este punto se finalizan el esquema y los formatos de las tablas para que puedan seguir analizándose.
En esta fase también se limpian, enriquecen, validan y deduplican los datos.
Prácticamente todos los programas ETL más conocidos disponen de algún tipo de función de limpieza de datos, con una interfaz gráfica de usuario fácil de usar que facilita la limpieza de los datos sin necesidad de grandes conocimientos técnicos.
La depuración se realiza mediante diversos métodos, en su mayoría a cargo de ingenieros de datos, analistas o administradores.
A continuación se detallan algunas técnicas utilizadas.
1. Uso de fórmulas de tipo SQL dentro de la GUI -
Fórmulas como
SELECT DISTINCT customer_id, email, name FROM customers; se puede utilizar para eliminar duplicados de coincidencia exacta. GROUPBY es otra expresión SQL que se utiliza para encontrar similitudes en un conjunto de datos.
En función de la complejidad de los datos, también pueden utilizarse algoritmos avanzados de lógica difusa para encontrar casi duplicados.
2. Reglas de validación de datos - Los formatos de fecha, los valores numéricos, las reglas desplegables, etc. se configuran para eliminar incoherencias.
3. Tratamiento de valores perdidos - Los valores nulos o ausentes también se marcan y se enriquecen o rechazan.
4. Algunas herramientas ETL también incorporan funciones conectar fuentes de datos externas para rellenar los campos que faltan
5. Normalización - Conversión de formatos incoherentes en una convención estándar. Por ejemplo; usd o USD a $ o
6. Validación de valores atípicos - Establecer reglas para encontrar valores muy alejados de sus rangos esperados. El conocimiento específico del dominio también entra en juego aquí para establecer niveles mín-máx, los umbrales de longitud de caracteres también pueden establecerse para diferentes propiedades y los valores atípicos pueden revisarse y rechazarse, enriquecerse o añadirse a un flujo de trabajo.
Carga - Por último, los datos depurados y transformados pueden cargarse en el sistema de destino, como un almacén de datos o un lago de datos, donde pueden analizarse o utilizarse para la elaboración de informes.
Estas son algunas herramientas de transformación para la limpieza de datos
Pegamento AWS
AWS Glue es un servicio ETL totalmente administrado ofrecido por Amazon Web Services.
Hemos tratado en detalle cómo las herramientas ETL pueden automatizar todo el proceso de centralización de datos en un lago de datos tras consolidar datos de varias fuentes.
AWS Glue funciona de manera similar, es decir, está diseñado para ayudar a los usuarios a preparar y mover datos entre varios almacenes de datos diferentes para que puedan utilizarse para análisis, aprendizaje automático y desarrollo de aplicaciones sin tener que administrar servidores o infraestructuras complejas.
Entre otros aspectos que se detallan a continuación, AWS Glue es una opción ideal para usuarios que buscan Integraciones Nativas dentro del ecosistema de Amazon [S3, RDS, Redshift, Athena, Lake Formation, CloudWatch].
A continuación se muestra un vídeo que muestra cómo Zoho DataPrep se puede utilizar para la limpieza y transformación de datos:
¿Por qué destaca AWS Glue?
- Perfiles de datos: Los rastreadores de AWS Glues analizan de forma autónoma las fuentes de datos (p. ej., S3, RDS, Redshift) para inferir modelos de datos, esquemas de tablas, tipos de datos y manejar variaciones de formato (CSV, Parquet). Esto se hace a menudo manualmente en otras herramientas ETL heredadas.
Beneficio: Rápida incorporación de datos desordenados o semiestructurados con una mínima definición manual de esquemas.
- Calidad de datos y perfiles integrados (Glue Data Quality): Glue incluye ahora funciones de calidad de datos que permiten definir reglas y restricciones (por ejemplo, "sin nulos en la clave primaria", "valor entre 0-100") y validar automáticamente los conjuntos de datos.
Beneficio: Control continuo de la calidad de los datos integrado directamente en el proceso de limpieza.
- Flexibilidad del código (Python + Spark): Ahora los usuarios pueden escribir lógica de limpieza personalizada con PySpark o scripts de Python directamente en Glue Studio. Glue también admite transformaciones personalizadas y limpieza basada en ML, como la coincidencia de entidades o la detección de valores atípicos, mediante AWS Glue ML Transforms.
Beneficio: Los desarrolladores obtienen tanto la automatización como el control total para escenarios de limpieza complejos.
- Ventajas de coste y mantenimiento: Como Glue no tiene servidor, los usuarios y las organizaciones solo pagan por el tiempo de computación utilizado por los trabajos, por lo que no es necesario mantener servidores ETL o una infraestructura de limpieza de datos.
Beneficio: Menor vida útil (coste de propiedad) para operaciones de limpieza de datos continuas o a gran escala.
Algunos aspectos de AWSGlue a tener en cuenta (con soluciones)
A pesar de las diversas ventajas y beneficios de AWSGlue, es importante entender que no es una bala de plata y los comentarios de los usuarios incluyen algunos informes de rendimiento deficiente
Latencia de inicio del trabajo
Los trabajos de encolado pueden tardar entre 2 y 5 minutos en iniciarse porque AWS necesita poner en marcha un entorno Spark administrado (especialmente para el primer trabajo del día).. Esto puede hacer que Glue no sea adecuado para cargas de trabajo ETL de baja latencia o en tiempo real.
Como alternativa, los usuarios pueden utilizar trabajos de Glue Streaming para canalizaciones casi en tiempo real.
Otra alternativa puede ser ejecutar en computación persistente (por ejemplo, AWS EMR o Glue for Ray) para casos en los que los tiempos de inicio son críticos.
Deriva de esquemas y datos complejos
Aunque DynamicFrames ayuda, Glue a veces malinterpreta los tipos de datos (por ejemplo, enteros como cadenas) o no infiere correctamente los cambios de esquema anidados. Esto significa que los trabajos posteriores pueden interrumpirse o producir resultados incoherentes.
Como técnica de mitigación, se puede
- Validar manualmente la inferencia del esquema en el catálogo de datos Glue.
- Utilice clasificadores personalizados para formatos de archivo no estándar.
- Implantar reglas de versionado de esquemas y validación de datos.
Depuración y observabilidad
Depurar los trabajos de Spark en Glue puede ser difícil, ya que los registros se almacenan en CloudWatch, pero pueden ser verbosos y difíciles de rastrear. Esto significa que la resolución de problemas de lógica de transformación o de calidad de datos es más lenta.
Como alternativa, los usuarios pueden;
- Utilice glue Studio para la creación visual de trabajos y la previsualización de datos
- Habilitar marcadores de trabajo y métricas para la depuración incremental
- Utilice puntos finales de desarrollo para pruebas iterativas (aunque pueden ser costosas).
Reseñas:
Matillion
A diferencia de muchas herramientas ETL en la nube tradicionales que se centran en gran medida en la orquestación de canalizaciones o flujos de trabajo centrados en el desarrollo, Matillion se posiciona como una "nube de productividad de datos" destinada a ayudar a los equipos empresariales a crear, automatizar y gestionar canalizaciones a escala sin necesidad de tener una gran experiencia en codificación.
Su atractivo proviene en gran medida de su fuerte alineación con los almacenes de datos en la nube modernos como Snowflake, Databricks, Redshift y BigQuery, donde ofrece procesamiento pushdown nativo para mejorar el rendimiento.
Matillion se ha creado para equipos que mueven, preparan y transforman con frecuencia grandes conjuntos de datos y necesitan una herramienta que combine flujos de trabajo visuales con extensibilidad.
Aunque se presenta como una solución de bajo código, ofrece suficiente flexibilidad para que los equipos de ingeniería personalicen las canalizaciones utilizando Python o SQL cuando sea necesario.
Matillion ofrece integraciones directas con más de 150 fuentes, que abarcan bases de datos, herramientas SaaS, almacenamiento en la nube y flujos de mensajes.
El siguiente vídeo muestra cómo se puede utilizar el lienzo visual de Matillion para extraer datos de varias aplicaciones en la nube en Snowflake y aplicar pasos de transformación arrastrando y soltando.
Una vez introducidos los datos, los componentes de transformación de Matillion ayudan a los usuarios a gestionar los pasos de asignación, deduplicación, reglas de validación y enriquecimiento. La mayoría de estos componentes están preconfigurados, lo que facilita la creación de un flujo escalable sin tener que programar manualmente cada paso.
La herramienta también es compatible con la orquestación de trabajos, la programación, CI/CD y los paneles de control para equipos que gestionan varias canalizaciones simultáneamente.
Algunos escollos
Aunque Matillion es una potente herramienta para los equipos de datos en la nube, existen algunas limitaciones que los usuarios señalan con frecuencia:
Consumo intensivo de recursos para grandes transformaciones: Dado que Matillion depende en gran medida del pushdown a los almacenes en la nube, una lógica SQL deficiente o unas transformaciones no optimizadas pueden dar lugar a elevados costes de computación del almacén. Algunos usuarios señalan que el ajuste del rendimiento se convierte en una tarea recurrente.
Curva de aprendizaje más pronunciada de lo anunciado: A pesar de que se comercializa como low-code, muchos usuarios mencionan que entender el comportamiento del almacén en la nube, las dependencias de los trabajos y los componentes de transformación requiere sólidos conocimientos de SQL y experiencia práctica.
Preocupación por los precios: Los sitios de reseñas como G2 mencionan que los precios basados en el consumo de Matillion pueden aumentar rápidamente para las organizaciones que actualizan con frecuencia sus proyectos.
En general, Matillion es más adecuado para medianas y grandes empresas con almacenes de datos en la nube establecidos y equipos que puedan gestionar tanto flujos de trabajo visuales como optimizaciones basadas en SQL.
Reseñas:
Zoho DataPrep
A diferencia de otras herramientas de normalización de datos ETL de esta lista, Zoho DataPrep se anuncia ampliamente como una solución "sin código" para conectar y compilar datos de varias fuentes y construir Canalizaciones ETL más rápido desplegando modelos GenAI.
Zoho, para aquellos que no lo sepan, es un gigante indio del software con varios productos de software B2B que abarcan CRM, contabilidad, gestión de personal y software de gestión de inventario. Por lo tanto, se puede asumir que saben una o dos cosas sobre la limpieza de datos, especialmente para los datos de clientes e inventario.
Zoho DataPrep cuenta con integraciones "Out of the Box" con más de 70 fuentes diferentes para reunir los datos en bruto en un solo lugar, esto incluye almacenes de datos, software empresarial, carpetas de unidades y almacenamiento en la nube.
En este vídeo se muestra cómo se puede utilizar la sencilla interfaz de arrastrar y soltar de ZohoDataPrep para extraer y combinar datos de 70 fuentes de datos diferentes.
La fusión de dos conjuntos de datos puede realizarse utilizando cualquiera de las funciones de unión incorporadas y, en la fase de "Transformación", pueden aplicarse lógicas de validación, deduplicación y fusión, así como pasos de enriquecimiento.
Aunque se puede utilizar como solución sin código, para utilizar este software de limpieza de datos es necesario tener conocimientos técnicos y de gestión de grandes conjuntos de datos.
Algunos escollos
Hay algunos casos en los que ZohoDataPrep puede no ser una solución ideal.
- Las limitaciones de capacidad inherentes son una de las principales razones. Así lo señala la propia Zoho "Documentación "Limitaciones. Por ejemplo, el # máximo de columnas está limitado a 400, el tamaño máximo para la importación desde formatos locales y otros es de 100 MB.
Esto hace que el software sólo sea adecuado para ejercicios de depuración de datos de tamaño pequeño a moderado.
- Algunos comentarios de usuarios de fuentes como G2 y el portal de la Comunidad de Zoho mencionan que el software tiene "fallos" cuando se trata de gestionar diferentes tipos de datos.
Múltiples instancias de campos importados con formatos "Fecha" o "Desplegable" importados como "TEXTO".
Scrub.AI
Scrub.AI se diferencia de las principales herramientas ETL o de preparación de datos al centrarse específicamente en la limpieza automatizada de datos y la mejora de la calidad mediante reglas basadas en IA.
Mientras que la mayoría de las plataformas ETL requieren una mezcla de configuración manual y creación de reglas, Scrub.AI se posiciona como un sistema de autoaprendizaje que identifica y corrige automáticamente los problemas de calidad de los datos a escala.
La plataforma es utilizada principalmente por equipos que trabajan con conjuntos de datos de clientes, proveedores, productos y transacciones en los que son esenciales la eliminación de duplicados, la normalización de atributos y la detección de anomalías.
Utiliza modelos de IA entrenados en conjuntos de datos específicos del sector para clasificar automáticamente los campos, detectar desajustes y recomendar correcciones con una intervención humana mínima.
La plataforma se integra con varias bases de datos y aplicaciones en la nube de uso común, y permite a los usuarios importar archivos planos, hojas de cálculo o flujos de API directamente en un espacio de trabajo unificado.
El flujo de limpieza de Scrub.AI se basa en perfiles automatizados, transformaciones basadas en IA, detección de patrones y pasos de enriquecimiento.
El sistema destaca los grupos duplicados, los valores que faltan, los formatos incorrectos y las estructuras de atributos incoherentes. Los usuarios pueden aceptar, rechazar o modificar cualquier recomendación generada por la IA durante la fase de revisión.
Algunos escollos
Aunque Scrub.AI ofrece velocidad y automatización, hay escenarios en los que la plataforma puede quedarse corta:
Control limitado de la lógica subyacente: A veces, los usuarios avanzados afirman que el enfoque basado en la IA oculta demasiadas cosas de lo que hace realmente la herramienta. Cuando se trabaja con conjuntos de datos complejos, los usuarios pueden desear más transparencia o la posibilidad de anular las suposiciones a nivel de sistema.
Depende de los datos de entrenamiento: Dado que la herramienta se basa en gran medida en modelos de IA preentrenados, su precisión varía en función del sector. Los comentarios de la comunidad sugieren que la plataforma funciona muy bien con datos de clientes o proveedores, pero puede tener problemas con atributos muy técnicos o específicos de un dominio.
No es ideal para archivos muy grandes o flujos de trabajo ETL completos: Scrub.AI es principalmente una solución de limpieza de datos, no una herramienta completa de orquestación o canalización. Los equipos que necesiten programación, versionado, integraciones en toda la pila u orquestación pueden tener que emparejarlo con otras herramientas.
Scrub.AI es ideal para organizaciones que necesitan mejorar la calidad de los datos con ayuda de la IA, pero que no necesitan una plataforma ETL o MDM completa.
Conclusión
La elección de una herramienta de limpieza de datos ya no consiste sólo en arreglar registros defectuosos, sino en crear una base de datos que pueda seguir el ritmo de las empresas de hoy en día.
La solución adecuada debe ayudar a los equipos a pasar de las limpiezas periódicas a un flujo constante y fiable de información precisa que respalde la planificación, el aprovisionamiento y las operaciones diarias. A medida que las organizaciones crecen, este cambio se vuelve esencial.
Un enfoque de limpieza estructurado, respaldado por una automatización inteligente, garantiza que los datos maestros sigan siendo fiables, reduce la carga operativa y, en última instancia, refuerza todos los sistemas que dependen de ellos.



