

Comparing the Best Software & Vendors for Data Cleansing
For any software system or organizational process to operate unfettered, the underlying data quality is equally important, if not more, when compared to the very technical systems and software platforms that depend on the data for continuity and accuracy of business operations.
Unfortunately, though, the availability and readiness of organizations to maintain data quality and augment it has not matched the pace when compared to other technologies.
Since 2021, immediately in the aftermath of the first public announcement of the conversational AI platform, ChatGpt, and the subsequent unveiling of agentic systems that can autonomously execute a myriad number of tasks, the debate on data quality is back on everyone’s mind.
This is particularly true as enterprises have come to the realization that even the best tech-enabled systems are useless or inaccurate in their output when the underlying data is incomplete, duplicated, unreliable and not synchronized with other data management systems.
The graph below shows an uptick in the number of searches by users looking to explore data cleansing services and tools for ensuring ongoing data quality thresholds.
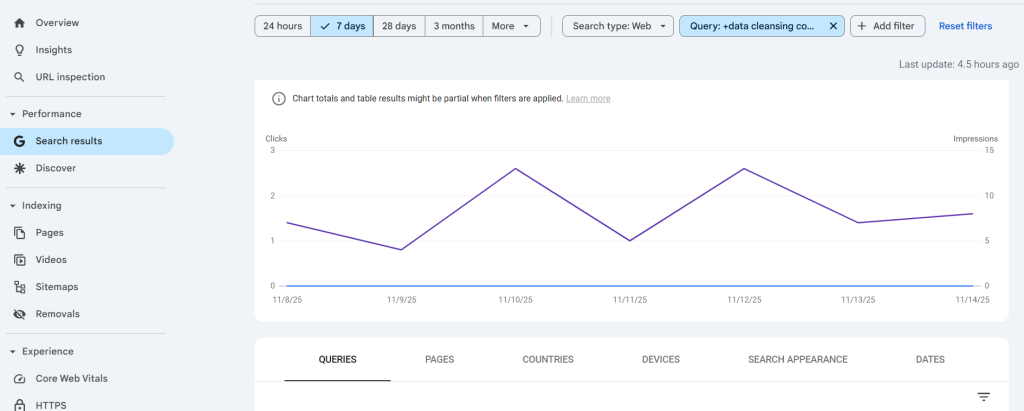
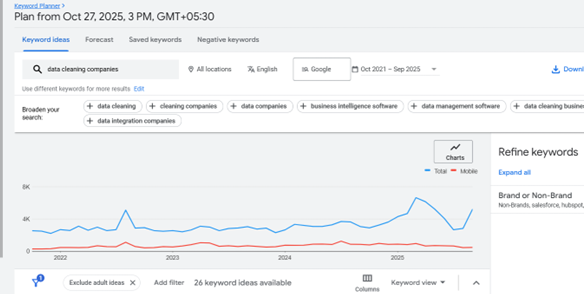
To equip buyers, procurement professionals, data management & GTM teams with the right information, this article compiles some of the leading data cleansing platforms, broadly categorized into the following.
- CRM Data Cleansing Software
- ERP Data Cleansing Software
- Employee & HR Data Cleansing
- One-off Data Cleansing [Custom]
#1, #2 & #3 from the above are common and recurring requirements, especially in the absence of poor data governance frameworks.
#4 however are unique, one-off data cleansing requirements that are custom in nature and typically not recurring as they are taken up on a project basis.
Also, this list will feature a wide-array of platforms for data cleansing tools, featuring ETL tools, purpose-built cleansing software, Open-Source platforms, Data Preparation software etc
Also, since data cleansing is a broad term, the tools detailed in this article are evaluated across their capabilities in;
- Normalizing data records into a structured format from an unstructured one
- Validation of Data
- Enrichment of Data Records
- Deduplication
- Integration with related data sets and technology systems
CRM Data Cleansing Tools
Most companies over a million $ in revenue typically make use of a CRM system. The objective of the CRM is to capture the journey stages of prospects, leads, opportunities and customers through the conversion cycle and equip sales, marketing and operation teams with the right data.
Some CRMs even capture partner data and associations between partners, leads and target accounts.
However, this data erodes over time as duplication, missing information, mistaken associations of data are common with go-to-market and business teams and best practices in data stewardship is not always maintained.
Openprise
Openprise markets itself as a data orchestration and automation platform designed to help companies manage, clean, and unify their data across marketing, sales, and operations systems.
The software’s unique selling point is seamless integration across multiple GTM-systems including CRM, ERP, customer data platforms (CDPs), advertising platforms and other third-party tools for outreach and intelligence gathering.
The image below showcases how OpenPrise powers Revenue Operations, Performance Marketing and business teams with clean, accurate and reliable data.
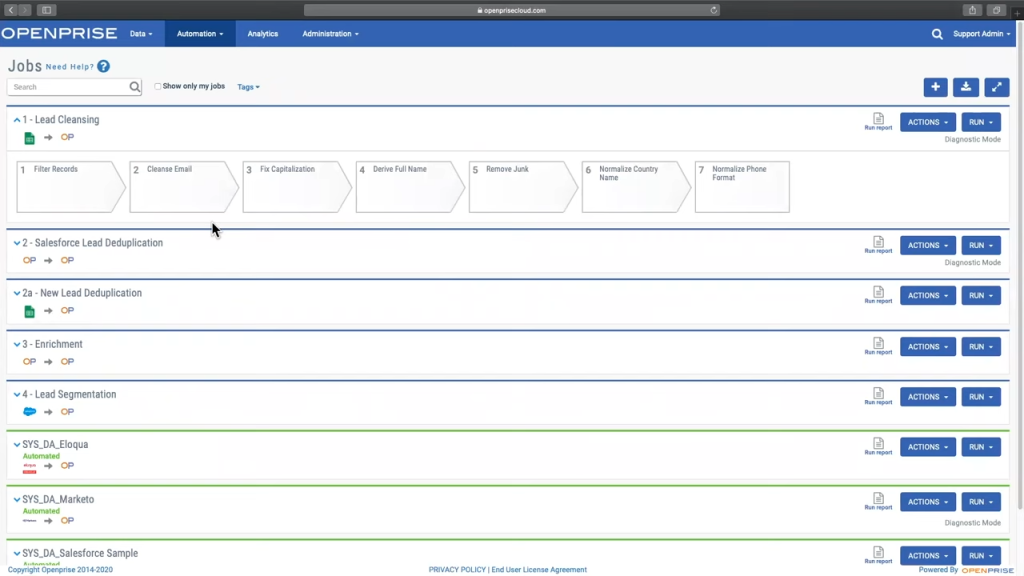
At a high-level, here are some of their core capabilities.
- Removal of duplicates at a contact and account level – by leveraging email address, website domains, semantic patterns and human-in-the loop
- Validation of email addresses and phone numbers to weed out Junk values
- Normalizing Addresses, Zip Codes,
- Inferring location data from phone numbers
- Inferring city or state data from ZipCode or vice versa
- Standardizing values and formats – for example: Title Case for Names, small case for emails etc
- Enrichment of missing values is also possible by integrating third party contact intelligence solutions
In addition to data cleansing, Openprise also offers some solutions to assign leads by scoring and routing them to the relevant owner.
Reviews:
Datablist
DataBlist positions itself as a practical data quality and list preparation tool aimed at teams that regularly handle spreadsheet-based datasets such as contact lists, customer records, product catalogs, or event-generated leads.
The platform primarily, focuses on helping business users clean, structure, and standardize large volumes of data without needing IT support or any kindof technical scripting, or heavy coding.
Its strength lies in providing a familiar, grid-style workspace where users can quickly review records, apply corrections, and harmonize values before loading the data into CRM, marketing, or operational systems.
The image below shows how Datablist detects the duplicates, and other data anamolies in datasets
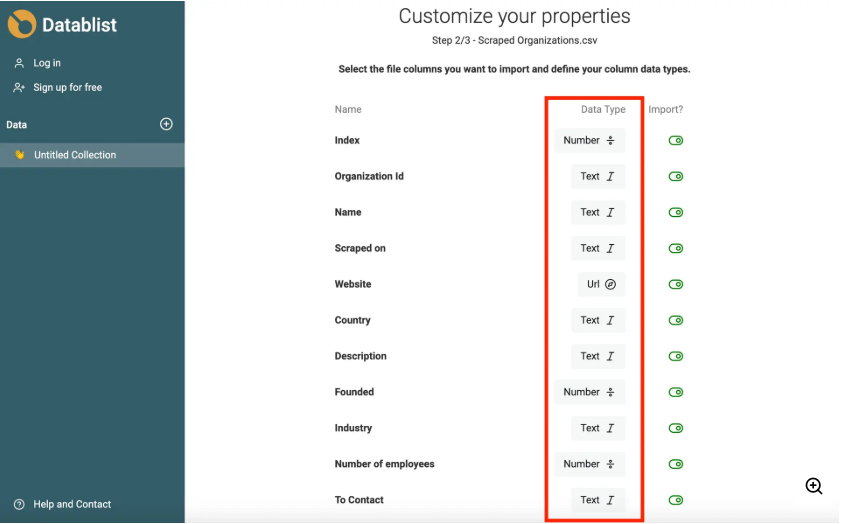
At a high level, DataBlist offers a set of practical capabilities that help teams clean up and prepare lists before moving them into their operational systems.
- Detects duplicates across names, emails, phone numbers, and company fields, allowing users to review and merge records cleanly.
- Flags invalid emails, incorrect phone formats, and missing mandatory values to reduce upload errors in CRM and marketing systems.
- Normalizes capitalization, phone and email formats, and other inconsistent fields across imported lists.
- Supports lookup-based enrichment and simple rules to populate missing states, classifications, or related fields.
- Splits long-form addresses, corrects mismatched city–ZIP combinations, and maps ZIP codes to states.
- Helps map and align columns when consolidating lists from partners, events, or older systems.
- Allows bulk transformations and conditional updates with a preview step to avoid accidental overwrites.
- Used as a staging layer to ensure data enters Salesforce, HubSpot, outreach tools, procurement systems, and reporting platforms in a clean and consistent form.
Overall, the platform gives operations and RevOps teams a practical environment to review, correct, and structure their data so it moves smoothly into the systems that depend on it.
Reviews:
ERP Master Data Cleansing
An ERP system is typically used mostly by enterprise companies and is far less common than a CRM system.
Typically, an ERP system does not co-exist with a CRM as it already captures most of the intended purpose of a CRM system. Although this may not necessarily be the case.
An ERP system is also much broader in its scope and cannot even be compared with a CRM.
ERP and EAM systems manage all functions including production planning, human resources, financial management and accounts in addition to go to market-specific operations.
These systems are typically in-use at enterprise accounts where the total volume of records is generally quite large and scattered making a data cleansing exercise far trickier.
The types of data cleansing changes from time to time.
- Cleansing “Material” Data
- Cleansing of “Customer” Master Data
- Cleansing of “Supplier” Data
- Cleansing of “Services” Data
- Cleansing of “Fixed Assets” Data
Verdantis MDM Suite
Verdantis specializes in enterprise software solutions, particularly for asset-intensive organizations. Verdantis’ MDM suite is a purpose-built software that for managing master data quality for data domains that are specific to production data.
The software is trained on data records specific to the below industries and deploys agentic AI for fixing data quality gaps across all master data domains.
The two modules available in Verdantis MDM suite are Harmonize and Integrity;
Harmonize: This module is focused on normalizing, cleansing and enriching legacy master data records by collating them not only from the ERP or EAM systems but also from multiple unstructured sources like supplier invoices, asset bill of materials, third party intelligence sources like D&B, ZoomInfo etc
Integrity: As the name suggests, Integrity is a module that solves for master data governance, covering the same data domains as mentioned above. This module integrates with multi or single-environment ERPs, master data stack or EAM systems to build a process and manages every master data record entry a the source itself.
The module Integrity is designed to ensure;
- The time required for creation of a master data record is slashed
- The accuracy and completeness (Integrity) of the master dataset is maintained as the records are created on a going basis
The idea behind master data, ERPs and operational excellence, in general, is to reduce execution time for tasks and data entry, stewardship are functions that are resource intensive, especially in terms of human capital.
To reduce this, Integrity syncs with other enterprise modules and validates the record creation in real time – highlighting potential duplicates and missing mandatory information.
It also goes one step further and deploys AI agents to auto-complete missing information from verified third party sources like supplier catalogues, databases, intelligence software and even maintained list of websites.
The video below, showcases how Integrity operates within Verdantis’ MDM suite to manage record creation and governs enterprise master data records on a going basis.
Ataccama ONE
Ataccama is a unified data management platform built for enterprises that want to bring together master data management (MDM), data quality, governance, and automation under a single roof.
Its core offering, Ataccama ONE, is an integrated solution that supports not just MDM, but also data profiling, observability, lineage, reference data, and agentic AI-driven automation.
The video below will walk you through the core capabilities of how Ataccama works:
Ataccama ONE is structured around modular capabilities, the two most prominent being:
– Data Quality & Observability: The module automates data profiling, AI-driven quality checks, and real-time monitoring. It detects anomalies, suggests fixes, and supports cleansing and enrichment across all key data domains.
– Master Data Management: The MDM module creates governed, reliable master records across domains. It integrates with ERPs and enterprise systems to manage creation, enrichment, approval, and publishing, using unified matching and deduplication to maintain a consistent, trusted golden record.
The goal of this module is pretty straightforward:
Reduce the time and manual work involved in creating or updating master records
Keep the data accurate, complete, and properly validated
Provide clear visibility into who changed what and when, using lineage and approval tracking
To make this work, Ataccama ONE checks every new or incoming record in real time. If something is missing, duplicated, or formatted incorrectly, the system flags it before the data is saved into downstream systems.
Ataccama works with enterprises across the BFSI, telecom, pharma, and government sectors, with noteworthy clients such as Aviva, UniCredit, T-Mobile, Roche, and Philip Morris International.
Reviews:
SAP MDG
SAP is arguably the pioneer and the first-mover in ERP master data management. MDG, short for master data governance, was launched by SAP in 2010 and solves for enterprise requirements in maintaining master data quality.
One of the biggest selling points for SAP MDG is the ecosystem support in extracting and collating the data from SAP-specific systems. Users can directly extract or integrate MDG with their SAP-ERPs, EAM, SAP PM and a whole plethora of SAP-native software.
With that said, there are a few limitations with SAP MDG that make it a difficult for enterprise to implement this for their master data requirements.
- Limited AI & Automation Features
With the “Central Governance” mode in SAP S/4HANA (Feature Pack Stack 2) and private-cloud editions, MDG supports natural-language prompts for making field changes and can auto-generate summaries of changes.
SAP has introduced Joule, a generative AI assistant/copilot built for SAP cloud applications. It’s grounded in business data, supports natural language, and has autonomous “agent” capabilities.
Despite these announcements, Practical use-cases of AI-specific features in SAP MDG seem limited, at the time of writing this post.
Even though AI agents are being promoted, in MDG the agentic autonomy (i.e., fully autonomous decision-making agents in MDG) is still somewhat limited. For example, the G2 feature list shows that for “Agentic AI – Autonomous Task Execution / Multi-step Planning / Adaptive Learning” there is “Not enough data”.
- Non-SAP Integrations can get Complex & Expensive
Depending on the nature of business and the industry, master data requirements at any enterprise are heavily dependent on the “Data Domain” in question.
An enterprise with asset-intensive operations, for example will require advanced data cleaning capabilities, in Materials, Fixed Asset (equipment) and Supplier data domains.
Similarly, a “SaaS” or “Services” specific enterprise may require advanced data cleaning capabilities across “services” and “customer” data domains.
For building these capabilities and retrieving data, a bi-directional sync is necessary and this can be quite complex & expensive with non-SAP systems.
- Custom Domain Development is Complex
SAP MDG provides strong out-of-the-box support for key master data domains such as Business Partner, Material, and Finance.
However, when organizations need to manage additional or industry-specific data domains — for instance, Assets, Projects, Locations, or Equipment — they often face significant implementation complexity.
- Limited Built-in Data Quality Intelligence
While SAP MDG provides data validation and derivation rules, it lacks advanced data cleansing or matching algorithms.
Enterprises may need SAP Data Services (BODS), SAP Information Steward, or third-party tools (like Informatica or Trillium) for true data cleansing, enrichment, and duplicate detection.
Example: Detecting “duplicate customers” with slight name variations may require an external data quality engine.
Category | Strengths | Limitations |
Integration | Excellent with SAP landscape | Weak with non-SAP systems |
Data Governance | Robust workflows & roles | Can cause process bottlenecks |
Data Quality | Basic validations | Lacks advanced cleansing or AI features |
Customization | Highly flexible | Complex and time-consuming |
Cost & Effort | Enterprise-grade reliability | High TCO and setup time |
User Experience | Improved with Fiori | Still complex for casual users |
Reviews:
ETL/Data Transformation Tools
ETL software is great for unstructured data cleansing, especially when for one-off tasks where training-based frameworks or dictionary modifiers don’t exist.
ETL simply stands for Extract, Transform & Load. Put simply, the software extracts data from multiple third-party sources. Either via API connections or out of the box integrations.
The next step is transformation. At this point in time the table schema and formats are finalized such that it’s suitable of further analysis.
This is also the stage during which the data is cleaned, enriched, validated and deduplicated.
Pretty much all the popular ETL software have some sort of data cleansing capabilities, with a user-friendly GUI that make it easy to clean the data without much technical bandwidth.
The cleansing is done using a variety of methods, mostly performed by data engineers, analysts or stewards.
Some techniques used are detailed below.
1. Using SQL type formulas within the GUI –
Formulas like
SELECT DISTINCT customer_id, email, name FROM customers; can be used to weed out exact match duplicates. GROUPBY is another SQL expression that is used for finding gaps similarities in a dataset.
Depending on the scale of data complexity, advanced Fuzzy Logic algorithms may also be used for finding near-duplicates
2. Data Validation rules – Date formats, Numeric Values, dropdown rules etc are setup to do away with inconsistencies
3. Handling Missing Values – Null or missing values are also flagged and either enriched or rejected.
4. Some ETL tools also have built-in features to connect external data sources for populating missing fields
5. Standardization – Converting inconsistent formats into one standard convention. For example; usd or USD to $ or
6. Outlier Validation – Setting up rules to find values far outside their expected ranges. Domain-specific knowledge also comes into play here to set min-max levels, character length thresholds can also be set for different properties and outliers can then be reviewed and rejected, enriched or added to a workflow.
Load – Finally, the cleaned and transformed data can be loaded into the target system, like a data warehouse or a data lake, where it can be analyzed or used for reporting.
Here are a Transformation tools for data cleansing
AWS Glue
AWS Glue is a fully managed ETL service offered by Amazon Web Services.
We’ve covered in detail how ETL tools can automate the entire process of centralizing data into a data lake after consolidating data from several sources.
AWS Glue works in a similar way, in that, it’s designed to help users prepare and move data between several different data stores so it can be used for analytics, machine learning, and application development without having to manage servers or complex infrastructure.
Among other aspects that have been detailed below, AWS Glue is an ideal choice for users looking at Native Integrations within Amazon’s ecosystem [S3, RDS, Redshift, Athena, Lake Formation, CloudWatch].
Below is a video showing how Zoho DataPrep can be used for data cleansing and transforming:
What Makes AWS Glue Stand Out?
– Data Profiling: AWS Glues’ Crawlers autonomously scans data sources (eg: S3, RDS, Redshift) etc to infer Data Models, Table Schema, Data Types & handle format variations (CSV, Parquet). This is often done manually in other legacy ETL tools.
Benefit: Rapid onboarding of messy or semi-structured data with minimal manual schema definition.
– Built-in Data Quality and Profiling (Glue Data Quality): Glue now includes Data Quality features that let you define rules and constraints (e.g., “no nulls in primary key,” “value between 0–100”) and automatically validate datasets.
Benefit: Continuous data quality monitoring integrated directly into the cleansing process.
– Code Flexibility (Python + Spark): Users can now write custom cleansing logic using PySpark or Python scripts directly in Glue Studio. Glue also supports custom transformations and ML-based cleansing, such as entity matching or outlier detection, using AWS Glue ML Transforms.
Benefit: Developers get both automation and full control for complex cleansing scenarios.
– Cost and Maintenance Advantages: Because Glue is serverless, users & orgs only pay for compute time used by jobs so there isn’t really a need to maintain ETL servers or a data cleansing infrastructure.
Benefit: Lower lifetime (Cost of Ownership) for continuous or large-scale data cleansing operations.
Some AWSGlue Aspects to Watch out for (with Workarounds)
Despite the several advantages and benefits of AWSGlue, it is important to understand that it is no silver bullet and user feedback includes some reports of substandard performance
Job Startup Latency
Glue jobs can take 2–5 minutes just to start because AWS needs to spin up a managed Spark environment (especially for the first job of the day). This can make Glue unsuitable for low-latency or real-time ETL workloads.
As an alternative, users can use Glue Streaming jobs for near-real-time pipelines.
Another Alternative can mean running on Persistent compute (eg, AWS EMR OR Glue for Ray) for cases where startup times are critical
Schema Drift and Complex Data
While DynamicFrames help, Glue sometimes misinterprets data types (e.g., integers as strings) or fails to infer nested schema changes correctly. This means that downstream jobs can break or produce inconsistent results.
As a mitigation technique, one can
- Validate schema inference manually in the Glue Data Catalog.
- Use custom classifiers for non-standard file formats.
- Implement schema versioning and data validation rules.
Debugging and Observability
Debugging Spark jobs in Glue can be difficult as logs are stored in CloudWatch, but they can be verbose and hard to trace. This means slower troubleshooting for transformation logic or data quality issues.
As an alternative, users can;
– Use glue Studio for visual job authoring and previewing data
– Enable job bookmarks and metrics for incremental debugging
– Use development endpoints for iterative testing (though they can be costly).
Reviews:
Matillion
Unlike many traditional cloud ETL tools that focus heavily on pipeline orchestration or dev-centric workflows, Matillion positions itself as a “Data Productivity Cloud” aimed at helping enterprise teams build, automate, and manage pipelines at scale without deep coding experience.
Its appeal largely comes from its strong alignment with modern cloud data warehouses like Snowflake, Databricks, Redshift, and BigQuery, where it offers native pushdown processing to improve performance.
Matillion is built for teams that frequently move, prepare, and transform large datasets and need a tool that blends visual workflows with extensibility.
While it presents itself as a low-code solution, it still offers enough flexibility for engineering teams to customize pipelines using Python or SQL when needed.
Matillion offers direct integrations with over 150 sources, covering databases, SaaS tools, cloud storage, and message streams.
The video below demonstrates how Matillion’s visual canvas can be used to pull data from multiple cloud applications into Snowflake and apply transformation steps in a drag-and-drop fashion.
Once the data is ingested, Matillion’s transformation components help users handle mapping, deduplication, validation rules, and enrichment steps. Most of these components are pre-built, which makes it easier to assemble a scalable flow without having to manually script each step.
The tool also supports job orchestration, scheduling, CI/CD, and monitoring dashboards for teams managing several pipelines simultaneously.
Some Pitfalls
While Matillion is a powerful tool for cloud data teams, there are some limitations users frequently point out:
Resource-heavy for large transformations: Since Matillion relies heavily on pushdown to cloud warehouses, poor SQL logic or unoptimized transformations can result in heavy warehouse compute costs. Some users note that performance tuning becomes a recurring task.
Steeper learning curve than advertised: Despite being marketed as low-code, many users mention that understanding cloud warehouse behavior, job dependencies, and transformation components requires solid SQL knowledge and hands-on experience.
Pricing concerns: Review sites like G2 mention that Matillion’s consumption-based pricing can escalate quickly for organizations with frequent pipeline refreshes.
Overall, Matillion is best suited for mid to large enterprises with established cloud data warehouses and teams that can manage both visual workflows and SQL-driven optimizations.
Reviews:
Zoho DataPrep
Unlike other ETL data normalization tools in this list, Zoho DataPrep is widely advertised as a “No-Code” solution for connecting and compiling data from various sources and building ETL pipelines faster by deploying GenAI models.
Zoho, for those who are unaware, is an Indian software giant with several b2b software products spanning CRM, Accounting, Workforce Management and Inventory Management software. So, one can assume they know a thing or 2 about data cleansing, especially for customer and inventory data.
Zoho DataPrep boasts “Out of the Box” integrations with over 70 different sources to bring the raw data together in one place, this includes data warehouses, business software, drive folders and cloud storage.
The video here showcases how ZohoDataPrep’s user-friendly drag and drop interface can be used to extract and merge data from the 70 different data sources.
The merging of two datasets can be done using any of the in-built join functions and in the “Transform” stage, validation, deduplication and merging logic can be applied along with enrichment steps as well.
While one can use the software as a no-code solution, data management skills and a technical understanding of managing huge datasets is a pre-requisite to use this data cleaning software.
Some Pitfalls
There are some cases in which ZohoDataPrep may not be an ideal solution.
- Inherent capacity limitations is one of the leading reasons. This is noted in Zoho’s own “Limitations” documentation. For instance, Maximum # of Columns is limited to 400, Maximum size for import from local and other formats is 100 MB.
This makes the software suitable for small to moderate size data scrubbing exercises only.
- Some user reviews from sources like G2 and Zoho’s Community portal mention that the software is “buggy” when it comes to managing different data types.
Multiple instances of fields imported with “Date” or “Dropdown” formats imported as “TEXT”
Scrub.AI
Scrub.AI differentiates itself from mainstream ETL or data prep tools by focusing specifically on automated data cleaning and quality improvement using AI-driven rules.
While most ETL platforms require a mix of manual configuration and rule building, Scrub.AI positions itself as a self-learning system that automatically identifies and fixes data-quality issues at scale.
The platform is primarily used by teams working with customer, vendor, product, and transaction datasets where duplicate removal, attribute standardization, and anomaly detection are essential.
It uses AI models trained on industry-specific datasets to automatically classify fields, detect mismatches, and recommend corrections with minimal human intervention.
The platform integrates with several commonly used databases and cloud applications, and allows users to import flat files, spreadsheets, or API streams directly into a unified workspace.
Scrub.AI’s cleaning flow is built around automated profiling, AI-based transformations, pattern detection, and enrichment steps.
The system highlights duplicate clusters, missing values, incorrect formats, and inconsistent attribute structures. Users can accept, reject, or modify any AI-generated recommendation during the review stage.
Some Pitfalls
Although Scrub.AI offers speed and automation, there are scenarios where the platform may fall short:
Limited control over underlying logic: Power users sometimes report that the AI-driven approach hides too much of what the tool is actually doing. When dealing with complex datasets, users may want more transparency or the ability to override system-level assumptions.
Dependent on training data: Since the tool relies heavily on pre-trained AI models, its accuracy varies across industries. Community feedback suggests that the platform performs strongly on customer or vendor data, but may struggle with highly technical or domain-specific attributes.
Not ideal for very large files or full ETL workflows: Scrub.AI is primarily a data cleaning solution, not a full orchestration or pipeline tool. Teams needing scheduling, versioning, stack-wide integrations, or orchestration may have to pair it with other tools.
Scrub.AI is best suited for organizations that need AI-assisted data quality improvement but don’t require a full-fledged ETL or MDM platform.
Conclusion
Choosing a data cleansing tool is no longer just about fixing bad records; it’s about building a data foundation that can actually keep up with how fast businesses operate today.
The right solution should help teams move from periodic cleanups to a steady, reliable flow of accurate information that supports planning, procurement and daily operations. As organizations scale, this shift becomes essential.
A structured cleansing approach, supported by intelligent automation, ensures that master data stays trustworthy, reduces operational drag and ultimately strengthens every system that depends on it.



